

Data Availability Vision
Abstract
From a client and developer perspective, the process of using a blockchain can be broken into three high-level steps: (1) computation tasks are submitted to the chain in form of transactions, (2) the blockchain processing the transactions, (3) inspecting the resulting state.
For a highly-scalable platform such as Flow, which we envision to process tens of thousand to millions of transactions per second, the events emitted during the a single block’s computation and the resulting state changes will be beyond the capacity of any single server to process. The Flow network itself shoulders this massive computation and data load via its horizontally-scalable, pipelined architecture. However, the approach commonly adopted in the blockchain space, to just run a single computer replicating the entire space and computation becomes intractable at Flow’s scale.
In the following, we describe Flow’s long-term vision how clients and developers of the Flow network can reliably and trustlessly query and replicate the subsection of the global state that is relevant for them. We emphasize that the design is byzantine fault tolerant [BFT] and clients can receive correctness proof for all data they are interested in if they desire so.
Furthermore, Flow’s design enables smartphone-sized light clients that can operate entirely trustlessly without needing to download or store chain history.
Central concepts and terminology
Data Egress Node or Edge Node (as a collective descriptor for archive, observer, Access node). Edge nodes follow the chain (block headers), and maintain a (small) subset of execution state and event data.
Usage pattern that an Edge Node is designed for:
- online most of the time and continuously following new blocks and ingesting the relevant state and event data
- receive data once, verify correctness, store and index it locally
- many operations are executed on the same stored data
- if an edge node is offline for prolonged periods of time, it needs to catch up which can take some time; during the catchup period the edge node does not offer its normal services (system resources largely required for catch-up and newest data is not yet available)
Light clients are largely stateless. They do not have to maintain any execution state or event data. Though, they might store a negligible amount of data locally, such as some block headers and a few accounts’ states. Data that the light client serves to its user is fetched on demand (or streamed on demand if desired by the client).
Usage pattern that a Light client is designed for:
- very sparse data access, most data is only needed once and never again
- can operate on minimal hardware, e.g. browser plugins, embedded hardware controllers (such as ESP32), or smartphones
- prolonged periods of being offline do not substantially impact the light client
trusted vs trustless
Shipping correct data to the user / developer is paramount. While the Flow platform cannot universally guarantee data availability, we must unconditionally guarantee data correctness. There are two ways for guaranteeing data correctness:
(i) trusted: the user / developer trusts that the data source delivers correct data
(ii) trustless: the data source might deliver incorrect data. The user’s / developer’s software (edge node or light client) must recognize the data as incorrect during the ingestion process and drop it.
The general approach for trustless data access is that the data source transmits the requested information along with some cryptographic proof that allows the recipient to verify the data’s correctness. Flow is architected such that these proofs are extremely data efficient, requiring only one or a few rounds of communication between the data source and the recipient.
The only requirement is a single block header (aka ‘anchor of trust’) that the user must supply once during the initial installation of the data recipient.
For Flow, it is well understood how light clients can cover large time periods. Conceptually, a light client can step through epochs, needing to fetch only 20 to 40 block headers per epoch. Thereby, a light client can scroll through weeks, months and years with minimal work.
Generally, execution state data and event data is tied to blocks. The first step for the data recipient is to established correctness of the block header, which entails verifying correctness of the consensus nodes’ signatures on the block. The block header contains a cryptographic commitment to the payload, which contains execution receipts and seals, which in turn commit to state and event root hashes. These are all merkle’ized data structures, which enable the data source to selectively generate proofs about the sub-structures that are of interest to the recipient.
Furthermore, these proofs can be batched by the data source in most cases and transmitted to the recipient in one message.
Long-term goals
Flow is architected to scale beyond 1 million transactions per second. You can read the details in this paper.
- A short- to mid-term goal is to support
• the state exceeding 1 petabyte in size (snapshot at one specific height) and
• the network producing gigabytes of event data every few seconds. - Trustless operations, including trustless data egress, is a central value proposition of Flow. In all likelihood, some data egress functionality will be technically intractable to implement in a trustless manner, too large of an engineering lift to implement compared to its utility, or not economically viable for clients to use due to disproportionate cost of the proofs.
Nevertheless, we strive to keep the data egress functions that are only available via trusted sources as small as possible. The important data egress functionality must be available in a trustless manner. Otherwise, we would substantially weaken the value of Flow as a decentralized, trustless platform, if core data egress functions are available only through trusted/centralized entities. - We want to support trusted data egress as well, because omitting proofs substantially reduces hardware and energy consumption. Trust relationships based on legal or economic incentives are very common, and we should allow clients to utilize such to improve efficiency and decrease cost.
- We want to enable developers to run their own edge nodes at small costs, allowing them to locally access the subset of state and event data that is relevant to them. Edge nodes must eventually allow getting their input data in a trustless manner for all prevalent use cases.
- We want users to be able to run light clients. Light clients must eventually allow getting their input data in a trustless manner for all prevalent use cases.
- Low-latency data access.
Implications
In the long-term, trustless data access cannot be contingent on maintaining the full state and/or consuming all events from blocks, as this would necessitate downloading gigabytes of data per minute and maintaining petabytes of state (for the mature network).
Therefore, for long term goal (2), we need to support trustless retrieval of a sub-set of the state and a subset of the event data.
In the mature network, execution nodes will probably dominate the energy and hardware consumption and of the entire network by a large margin. We envision execution nodes to be full data centres, while consensus and collector nodes are individual commodity servers and an individual verification node is maybe an agglomerations of a few servers.
On the one hand, decentralization is guaranteed by collector, consensus and verification nodes. On the other hand, the low number of execution nodes keeps the energy and hardware requirements of the network sustainable. Execution nodes only power through the huge amount of computational work, that the other decentralized collector and consensus committees line up for them. The decentralized swarm of verification nodes guarantee that execution nodes produce correct results.
Therefore, we cannot scale up the number of execution nodes without dramatically worsening the energy and hardware consumption of the network.
Vision for the Data Egress network
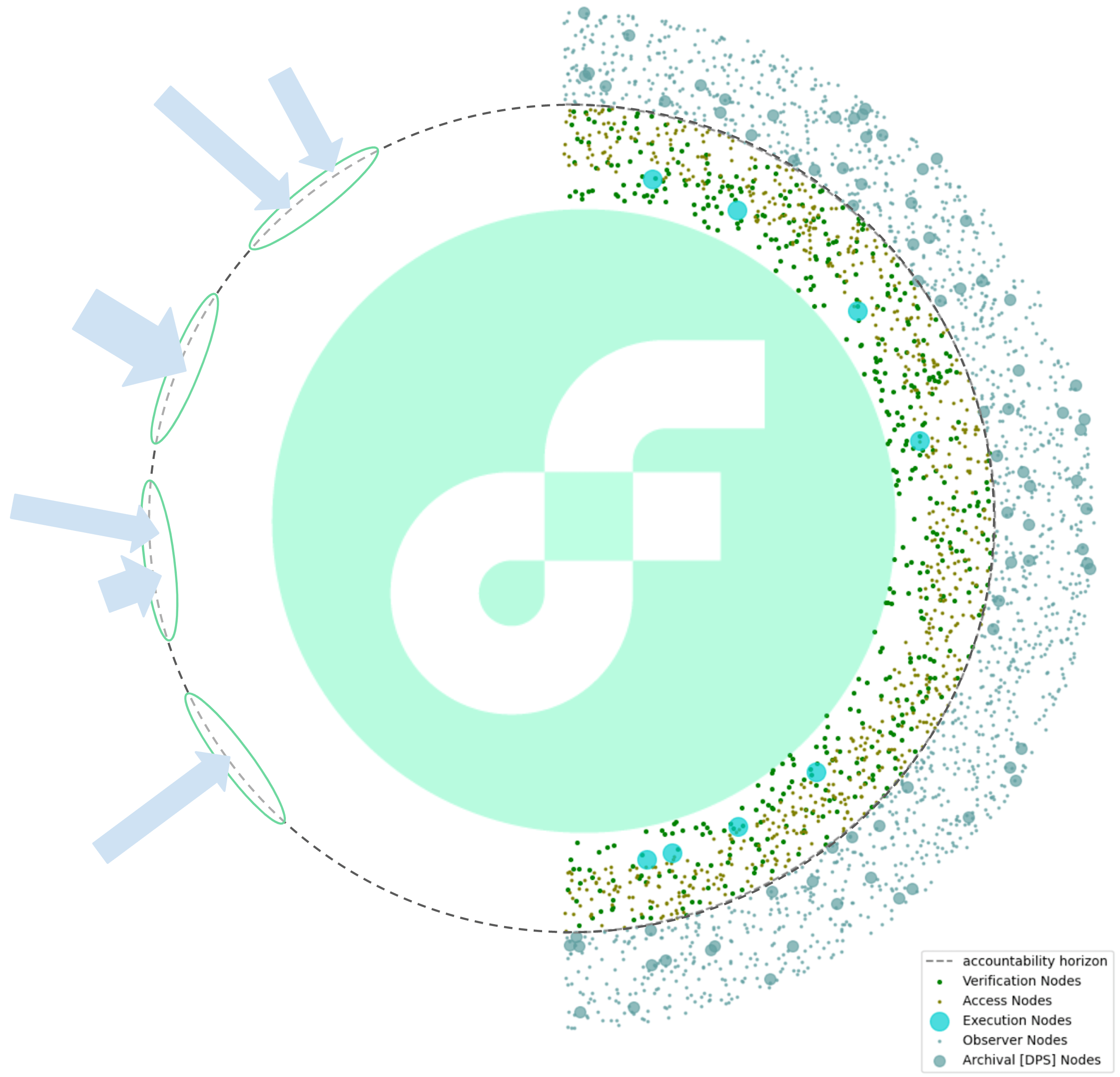
Verification and Access Nodes as tier-1 data replicas
In the long term, it will not be tractable for the Execution nodes to individually supply each node in the data egress network with its desired execution state and event data. This is because there are only 8 Execution nodes in the entire network and presumably thousands of edge nodes and billions of light clients.
Conceptually, there is a well-established solution to this data replication challenge: Execution nodes replicate their data to a larger yet still limited number of “tier-1 data replicas”, which in turn replicate to the data egress network. To make this layered data replication resilient to sibyl bandwidth exhaustion attacks and faulty-data-injection attacks, the tier-1 replication layer should be staked.
Furthermore, we must account for the fact that there is no intrinsic incentive for execution nodes to supply data to the external world. Empirical evidence shows that node operators are generally willing to support the network they are part of through auxiliary services, even without direct monetary compensation, because they indirectly benefit from increased adoption. However, should the free service their node provides become a substantial cost factor, node operators will stop providing such services on a goodwill basis. Hence, it is key to keep the cost of state and event replication low enough for execution nodes so it doesn’t develop into a significant pain point.
This brings us to an important insight:
Execution nodes have an immediate incentive to provide verification nodes with the necessary data. This is because without the verifier’s approvals, execution results are not sealed by consensus nodes and the execution nodes do not receive rewards. Furthermore, the cost of sending data to the verifiers is covered by the Execution node rewards. In the mature protocol, there will be about 60 to 250 verification nodes assigned to recompute each chunk. As part of their verification work, the verification nodes locally regenerate exactly the same data as the execution node. In other words, for each chunk there are at least 2/3·60=40 to 2/3·250=166 additional nodes in the network that possess exactly the data the edge nodes are interested in. Essentially, the Flow network already has the tier-1 data replicas, including an incentive mechanism for the execution nodes to supply them with data.
It is a very reasonable assumption that the cost will be low enough for supplying the edge nodes with data for free, if verification nodes also share some of the load.
Execution and Verification nodes are required by the protocol to only maintain a limited history of data
The data in the execution and verification nodes has only a limited life time. The purpose of execution and verification nodes is to advance the network, but not for long-term data archiving.

Unstaked Observer and Archive Nodes as tier-2 data replicas
Observer and Archive nodes are unstaked. They would get execution state data from the staked Execution, Verification and Access. As discussed above, the implicit benefits of a flourishing ecosystem probably provide significant incentive for Execution, Verification and Access Nodes to provide this service without explicit compensation, if all of these nodes share the operational load for the data egress. Furthermore, Observer and archive nodes should by default also share the data they store locally amongst each other (e.g. using the bitswap protocol, that works quite similar to bit torrent), which further reduces the load on the staked nodes (at least all data that is not absolutely the newest).
Enforcing data transfer from one party to another is a hard problem in byzantine environments, because lack of communication is subject to the Fisherman’s dilemma. If the data transfer fails, an outside party cannot attribute whose fault it is (at least not without recording the data request and the response in a blockchain, which is intractable in this case due to the large data volume).
Script execution is possible on all Edge nodes (Access, Observer, Archive Node) if desired by the operator
Script execution is an add-on service that can be added to any edge node. The edge node’s owner should be able to configure whether their edge node provides script execution as a service to the community, or whether they only want to offer private script execution.
Replicate data optimistically without waiting for sealing
We aim to make data available to the external clients as soon as it is executed (goal 6.) Waiting for sealing is not a long-term option, as sealing by itself adds some seconds of latency.
As soon as an execution node has committed to its result (execution receipt recorded in block), we have a relatively high assurance for its correctness, because the execution node would be slashed if the data is later found to be incorrect. In most cases, this could be a sufficient guarantee for clients to accept the execution result.
Nevertheless, for safety-critical applications, the clients may want to wait for sealing. We want to make the option available to clients to choose the assurance level that provides an optimal tradeoff between safety and latency for their particular application. In particular, a client should be able to specify whether it is willing to trust some particular execution node(s) and accept their results as soon as they are available. Another practically useful option could be for client to specify that they desire at least k execution nodes to have committed to the same result before accepting it. A very small number of available conditions would likely be already immensely useful.
Rich support for observing state transitions, i.e. utilizing events
Context:
Flow is a computation platform, with the central goal to maintain an execution state and evolve this state over time through state transitions. The state (at the end of a block) is well observable through cadence scripts. But the state transitions lack observability. We have events that can expose information about the state transition (similar to log messages of conventional software).
Impact (hypothesis)
In many cases, things happening on-chain are relevant for the outside world. But it is hard (conceptually complex and engineering intensive) for developers to build systems that follow what happens on-chain. Thereby, we create an incentive for a developer to move their logic off-chain into an environment they control and that is easily observable for them. Then, Flow is used like a data storage system, where all the logic happens off-chain and only the result is committed back to the chain.
However, moving logic off-chain undermines Flow’s value proposition of composability. If there is little logic on-chain, there is nothing to compose or build on-top. The value of composability critically hinges on a great platform experience for observing state transitions, i.e. supporting data-rich events.
Long-term Vision:
Filtering and indexing as a service on Edge nodes including trustless event retrieval.
The following filtering functions are potentially broadly useful to address the majority of use cases:
- filtering by type of event
- secondary filtering on event fields by their value (bucketing could be a viable approach, similar to prometheus)
- Type hierarchy for events (probably requires additional cadence features). This would allow queries like “give me all NFT-mint events”. Conceptually, this is very similar to interfaces in programming languages, just applied to data structures. When a developer is specifying that their event is ‘of type NFT-mint’, the event must at least contain the data fields as specified in the abstract type (and potentially more).
- streaming support, where clients can register web hooks and respective event filters with an edge node and have the subset of events they are interested streamed to them
Indexing and aggregation of events (see next section)
Native data indexing and aggregation
Established solutions for data indexing in the blockchain space can broadly be divided into the following two categories:
Centralized (example: Alchemy):
- require trust
- subject to protectionism, special interests, oligopolies, etc
- very hardware and energy efficient and thereby also cost efficient
- can cover all use cases that are computationally tractable
Decentralized (example: The Graph)
- allows for decentralized access
- facilitate composability
- incur higher hardware and energy overhead and thereby less cost efficient (larger redundancy is required for safety of decentralized platforms)
- overhead (higher redundancy) will be prohibitive for a noteworthy section of compute-intensive indexing and aggregation use cases
Axiom:
We assume that there is utility in having decentralized data indexing and aggregation due to its decentralized and open nature as well as resilience to cyber attacks and natural disasters.
Common approach for decentralized data indexing and aggregation:
Computational platform (layer-1 blockchain) is bridged to decentralized data indexing network like The Graph.
Downsides:
- bridging incurs high latency
- significant developer overhead, because they have to write code for two ecosystems
- usage overhead: original blockchain and The Graph each have their own token
- indexes and aggregates are not available to smart contracts on the original blockchain, because they live in a different ecosystem
Insights:
- The layer-1 blockchain computes something. Subsequently, The Graph ingests a subset of state + events and performs indexing and aggregation. Essentially, we have a layer-1 compute platform, whose results are ingested by a layer-2 compute platform for the purpose of post-processing.
- This approach of coupling two compute platforms has developed, because blockchains are commonly much too weak to handle the computational loads and data storage required for indexing and aggregation. So people accept the substantial overhead and performance costs of coupling compute platforms. Conceptually, it is just another case of sharding.
Long-term Vision
Flow is architected to handle large computational loads and store a massive state. As opposed to most (all?) other blockchain-based compute platform, Flow will have the power to run data indexing and aggregation natively within the platform. In fact, many indexing and aggregation computations are exceptionally suitable for concurrent execution, which is very effective for Flow’s large execution nodes.
Instead of burdening developers with writing code for two ecosystems, dealing with two tokens, high latency and no proper access to the indexes and aggregates from the original layer-1 smart contracts, we should provide indexing and aggregation functionality natively within Flow. This is very much in the spirit of Flow, because we don’t outsource complexity to the developer but absorb it into the platform. Thereby, the platform solves the problem once, instead of having developers solve the same problem over and over again. We increase utility of the Flow platform and free the developers to focus on their creative ideas instead of spending their time working around the platform limitations.
TLDR: in such a design, there are no correctness guarantees. Such system would be extremely vulnerable to wrong data, spamming and scams, and therefore most likely provide no utility.
Reason:
- data indexing and aggregation generally requires turning-complete computation
- correctness of the inputs (coming from the blockchain) can generally be established via cryptographic proofs
- But truthful execution of the data indexing and aggregation algorithms cannot be easily verified. Therefore, the resulting indices and aggregates are vulnerable to easy manipulation and censorship.
- The Graph works around this by introducing a token and requiring indexer nodes to stake, and introducing redundancy. Thereby they can slash faulty indexer nodes and enforce correct results. The Graph’s network has strong resemblance with a blockchain, for specifically the reason to enforce correctness.
Flow already has all the mechanics to enforce truthful execution and the computational capacity to handle this load.
Progressive evolution towards the final vision
Current state

- data is only shared to Observer and archive and once sealed
- observer and archive nodes must ingest the full state delta for each block (all or nothing)
- trustless (cryptographically verified) data ingestion for Observer/Archive node
- Observer/Archive nodes offer trusted, poll-based data access API to community
Important observations
Conceptually, the trie is only needed to prove data correctness to somebody else. With a perfect local data storage system, the Observer/Archive Node would theoretically not need the trie at all (unless the node wants to generate state proofs for somebody else). Keeping a versioned key-value store is conceptually sufficient for script execution.
Even without a trie, the Observer/Archive Node can cryptographically verify its inbound data as long as it ingests the full state delta and all events for each block. This requires some revisions of the chunk data pack and the verification node, but this is only be a moderate engineering lift.
The Observer/Archive node uses its local trie to
- recompute and thereby verify the correctness of the input data
- figure out whether a register in the chunk-data pack was only read or updated
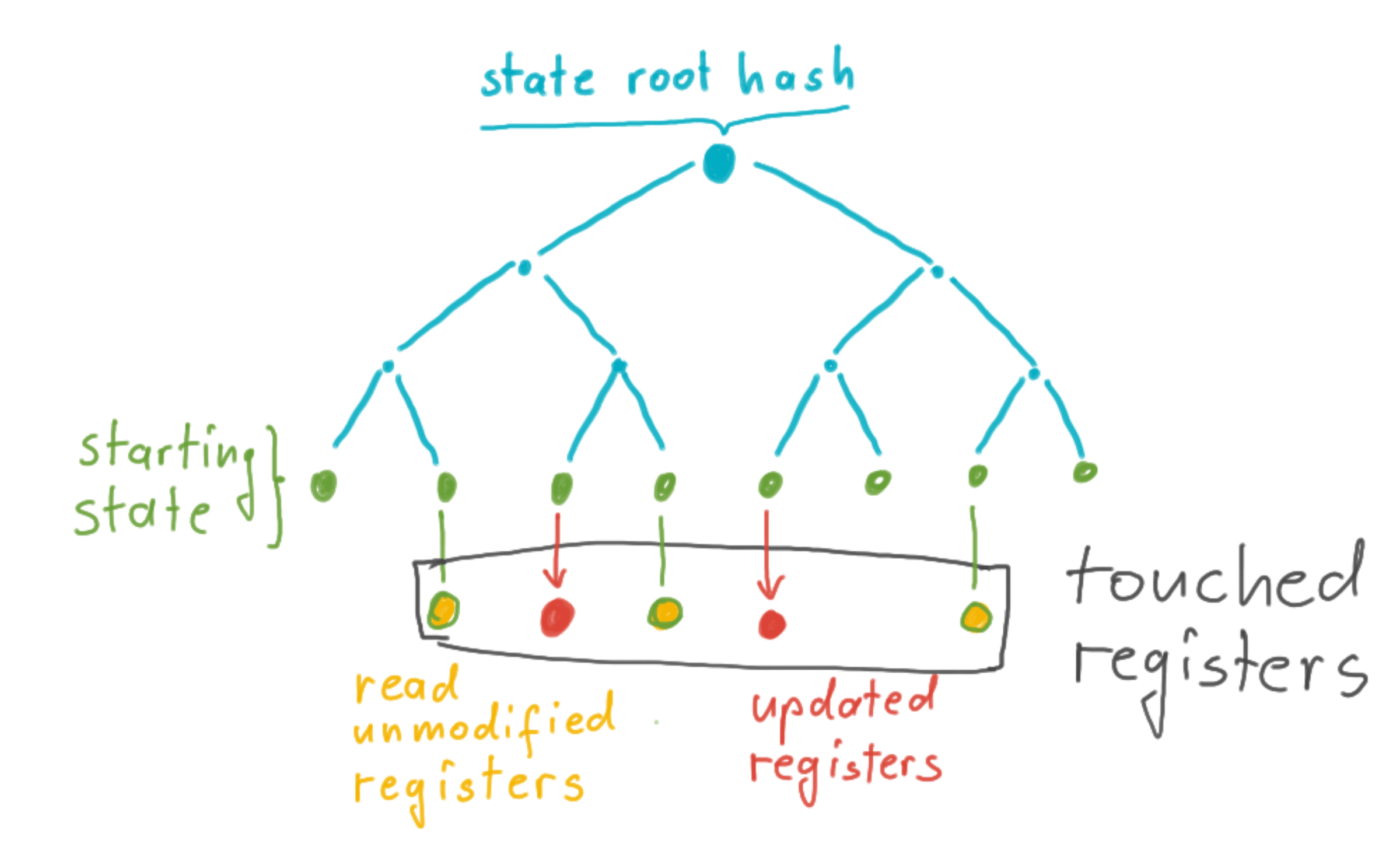
Alternatively, the Observer/Archive could
- Hash the chunk data pack (or section thereof it downloads) and verify that this data is consistent with what the execution node committed to. As the verification nodes also check the chunk data pack, correctness of the register in the chunk data pack can be established without needing the trie.
- In its current form, the chunk data pack lists all touched registers but does not differentiate between read-unmodified registers vs updated registers. However, in the chunk data pack, we could easily separate the updated registers from the ones that were only read. This would also reduce networking load on the Observer/Archive nodes as they could selectively download only the updated registers.
- This requires some minor restructuring of the chunk data pack and potentially some minor additional checks in the verification nodes. Then, we would not need the trie in the Observer/Archive Node anymore (unless we wanted to generate state proofs for clients).
At the moment, the execution state and event data is still small. Therefore, it conceptually possible to replicate the entire state and event data even on commodity hardware.
It is important to notice that we are currently susceptible to slow, hidden data decay. Possible sources would be disk errors, data base bugs, or bugs in the Observer/Archive node. However, this is predominantly a long-term concern.
Furthermore, also the trie as it is currently used in the Observer/Archive does properly solve this problem, because we only verify the state before we write it to the database. To the database, we write key-value pairs of the updated registers, whose correctness is equally well confirmed using the chunk data pack hash. Subsequent data corruption from disk errors or database bugs would also currently go unnoticed, even with the trie.
Evolution 1 (close to done)

- inish currently ongoing refactoring of Archive / Observer node → V2
(maturing the existing code and stability improvements) - Edge nodes run on commodity hardware [Done June 2023]
Remove the trie from DPS nodes. Instead they cryptographically verify the inbound data using the execution data hash.
- script execution on Edge nodes
- Indexing as a service provided by edge node to clients
• Initial version for trusted event (pre-) filtering on the edge node based on event type and smart contract
• Add trusted streaming support to access API for events, where clients can subscribe to events by event-type or smart contract that emits the events
- Optimistic data replication to Edge nodes (no waiting for sealing → latency reduction).
Details:
• Ingest results for a finalized block B as soon as an execution node’s receipt for B is embedded into chain (descending block that holds the receipt does not need to be finalized)
• Only report result to client if there is more than 1 execution node committing to same result (consistent with behaviour of current access API)
- Network-layer hardening (BFT work stream) will allow increased number of permissionless, potentially malicious access nodes (probably up to 20 byzantine access nodes + larger number of honest access nodes)
- Edge-node internal API to attach streaming and event-filtering
Observer/Archive nodes offer trusted, poll-based data access API to community
- trustless (cryptographically verified) data ingestion for Observer/Archive node
- Edge nodes still replicate the full state and event data (in all likelihood, that data will remain to be still small enough for full data replication to be practical using commodity hardware)
Outlook:
In 2023, we will work on the Binary Patricia Trie (aka “the new trie”). We expect that the development from beginning to end will take at least 6 months, realistically probably more like 9 months.
Binary Patricia Trie will bring support for storing the try in a data base (currently, the trie resides fully in-memory)
The Binary Patricia Trie (with support for hard-drive storage) will unlock a variety of strategically highly important features:
- server-side event filtering in a trustless manner
- Edge nodes to only download and maintain a subset of the execution state and events, which will allow them to continue to operate on commodity hardware even if the execution state becomes very large and blocks generate a massive number of events
- offer trustless data retrieval to the community
- support trustless light clients
- offer trustless script execution to the community (details: Script execution: vision and outlook)
With the Binary Patricia Trie, we can start building the trustless infrastructure in 2024 👇
Subsequent evolutionary steps

- include Verification nodes as tier-1 data replicas
- Mitigations for data decay (build on top of on-disk Binary Patricia Trie)
- Edge nodes can maintain subset of state and event data in trustless manner (requires trie-based proofs, including proof of data completeness)
- trustless data sharing amongst each other
- trustless streaming of filtered events to community clients
- type system for events allows filtering events by category
- second-level filtering by field values within events (e.g. give me only NFT-mint events, where rarity is “legendary”)
• first version can be trusted
• trustless version would be nice but might be too complex (potentially requires specific cadence support where developer specifies buckets as part of event’s type definition)
- trustless script execution
- community client can select their desired level of security:
• require sealed result
• unsealed result is ok, but only if there are consistent receipts from k different execution nodes (value for k is determined by community client)
• unsealed result is ok as long as it is from an execution node that the client trusts (list of trusted ENs is specified by client)
Smartphone-sized light clients
When envisioning light clients running on embedded hardware, including smartphones, there are three main challenges to solve:
- The amount of CPU cycles, memory, and storage that a light client can reasonably consume is extremely limited. You probably prefer to use your smartphone storage for photos rather than gigabytes of chain data.
- For a light client to be useful to an average end user, it has to deal with being offline for prolonged periods of time. Even if the light client were allowed to validate chain progress constantly by the operating system and user behavior, doing so would deplete batteries unacceptably quickly.
- Lastly, the light client must be able to catch up on multiple days of chain progress quickly and efficiently. Downloading all blocks is not an option. Imagine returning from a three-day camping trip, eagerly trying to check whether the trades for some NBA Top Shot Moments have succeeded – but your phone takes 20 minutes to download and validate all the block headers it missed… and runs out of battery.
These features are enabled through Consensus Follower. In a nutshell, the consensus follower is a library for tracking consensus progress trustlessly. The Consensus Follower independently applies consensus rules and locally asserts block finality. Essentially, it shields the higher-level processing logic from any malicious nodes sending invalid blocks. Unlike full consensus participants, the Followers do not need to validate block payloads in full — instead they can validate block headers only, utilizing the verification work already done by the consensus nodes.
Flow partitions time into Epochs, each one week long. Within this week, the set of staked nodes authorized to participate in network remains unchanged. If a node is slashed, the network might revoke their right to propose blocks for example, but no new nodes are added mid epoch.
At the epoch transition, the nodes authorized to run Epoch N hand the control of the blockchain over to the nodes for Epoch N+1. An intriguing feature of the Consensus Follower is that it only needs a few blocks from Epoch N, to assert the validity of any block header from Epoch N+1. The figure below illustrates this process. If you are interested how this works in more detail, we recommend this article.

While roughly 460,000 blocks are finalized during an epoch, a consensus Follower only needs to retrieve 0.005% of those blocks. Thereby, the Follower can fast-forward through months or even years of blocks consuming negligible computational and networking resources.
Furthermore, consider an Epoch (past or current) for which the Follower knows the authorized nodes. The Follower can trustlessly retrieve the state root hash for at an height belonging to the epoch without needing to know any ancestor blocks, by downloading a small chain segment and asserting its validity and finality. When knowing the state root hash at some block, it becomes possible to selectively retrieve part of the state in a trustless manner utilizing Merkle proofs.
Stay up to date with the latest news on Flow.
Stay up to date with the latest news on Flow.