

Upgrading Flow's Consensus Follower to boost attack resilience and processing speed

Earlier this year, Flow’s consensus team rolled out a major upgrade to our consensus algorithm. The upgrade reduced transaction finalization time by 30 percent and enabled faster, automatic recovery from network partitions, attacks and upgrades.
As part of this upgrade, the research team laid the technical foundation for an array of improvements to the Follower mode of the consensus algorithm, improving attack resilience and processing speed for all non-consensus nodes, including observer nodes, which anyone can operate without staking. We're excited to share that these improvements will be rolling out in the June 2023 network upgrade. In this article, we explain our improvements in more detail and their implications for the Flow network.
Participants and Followers in Flow's Consensus
Flow processes transactions in a pipelined manner, where five specialized node types — access, collection, consensus, execution, and verification nodes (all staked) — work together. In addition, there are non-staked observer nodes. In a nutshell, consensus nodes schedule transactions for execution by proposing new blocks and voting on them. The other nodes track the chain as it advances and perform the work as orchestrated by the consensus nodes.
Flow's consensus protocol supports two modes: Participant and Follower. A Participant is a node that actively contributes to advancing consensus via proposing and voting on new blocks. A central responsibility of Participants is to enforce block validity, by only voting on valid blocks and raising slashing challenges on invalid blocks. Consensus nodes operate in the Participant mode for Flow's main consensus [1].
The Consensus Follower is the module which allows any non-consensus node to track consensus progress trustlessly. The follower independently applies consensus rules and locally asserts block finality. Essentially, it shields the higher-level processing logic within the node from any malicious nodes sending invalid blocks. Unlike Participants, Followers do not need to validate block payloads in full — instead they can validate block headers only, utilizing the verification work already done by Participants.
Improvements
The new Follower implementation leverages the architectural improvements of our recent consensus upgrade by hardening nodes against various attacks, enabling the Follower to detect consensus violations, and lays the groundwork for extremely efficient light clients in the future.
The majority of improvements were unlocked by redesigning how and when Flow nodes validate Quorum Certificates (QCs). A QC is an aggregate of votes from a supermajority of consensus participants. While proposing or voting for an invalid block is a slashable protocol violation, the protocol still has to handle this scenario as individual consensus participants can be purposefully malicious (in technical terms ‘Byzantine’).
Flow employs Jolteon as its BFT consensus algorithm, which is an optimized flavor of HotStuff. In HotStuff, the QC for block B is included in B’s child block(s). A valid QC attests that a supermajority of consensus participants consider the block a valid extension of the chain. We say that a block B is certified, if and only if a valid QC for block B is known.
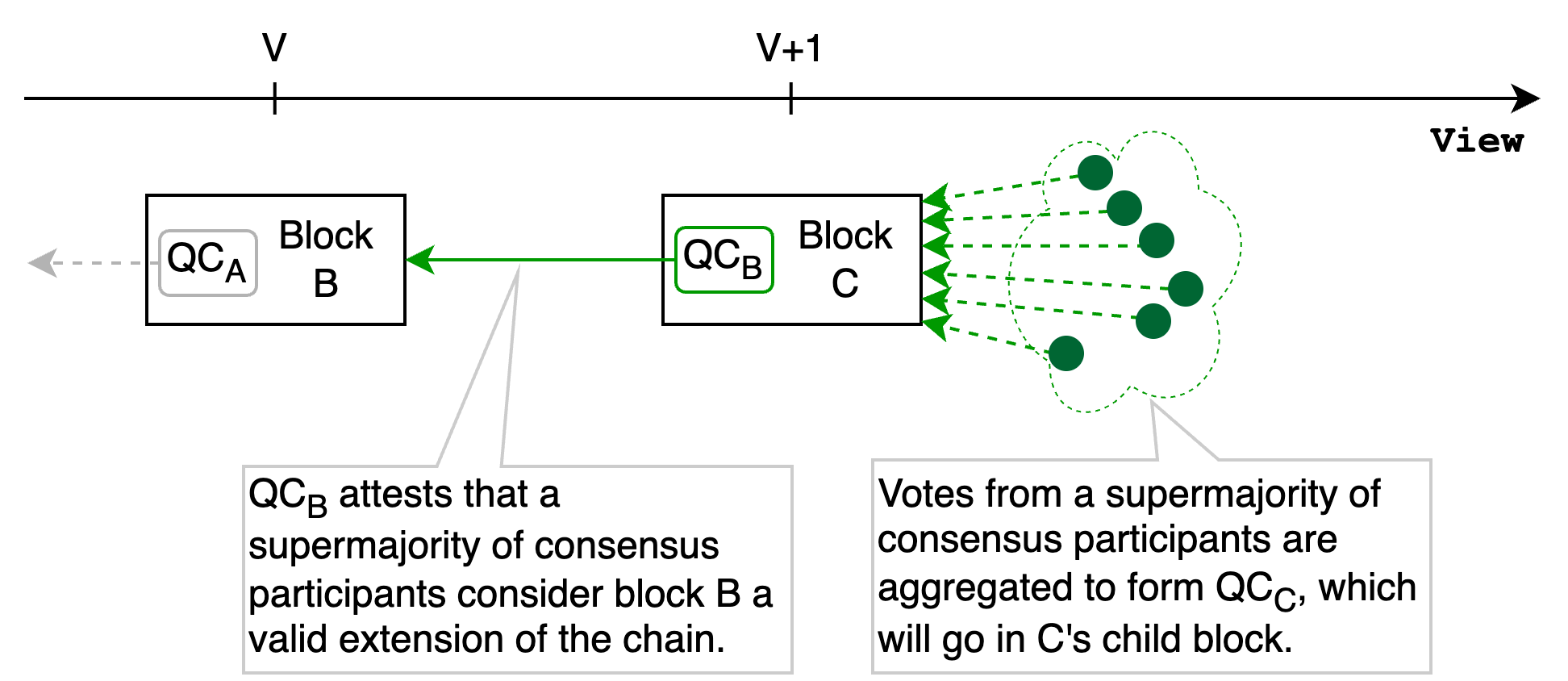
The Follower upgrade focuses on performance and resilience to Byzantine attacks. To mitigate attacks via invalid blocks, we re-designed the Follower’s internal processing of incoming blocks to:
- Validate block headers before they are cached
- Cache certified blocks separately from uncertified blocks
- Never store blocks which are invalid
Validate or Discard
In the previous version of the Follower, it was necessary to know a block's entire ancestry before we could validate the block’s header. For performance reasons, it is important to temporarily cache blocks, even if some ancestors are still missing.
The necessity to cache disconnected blocks could have been exploited as a vector for memory exhaustion attacks on the previous follower implementation:
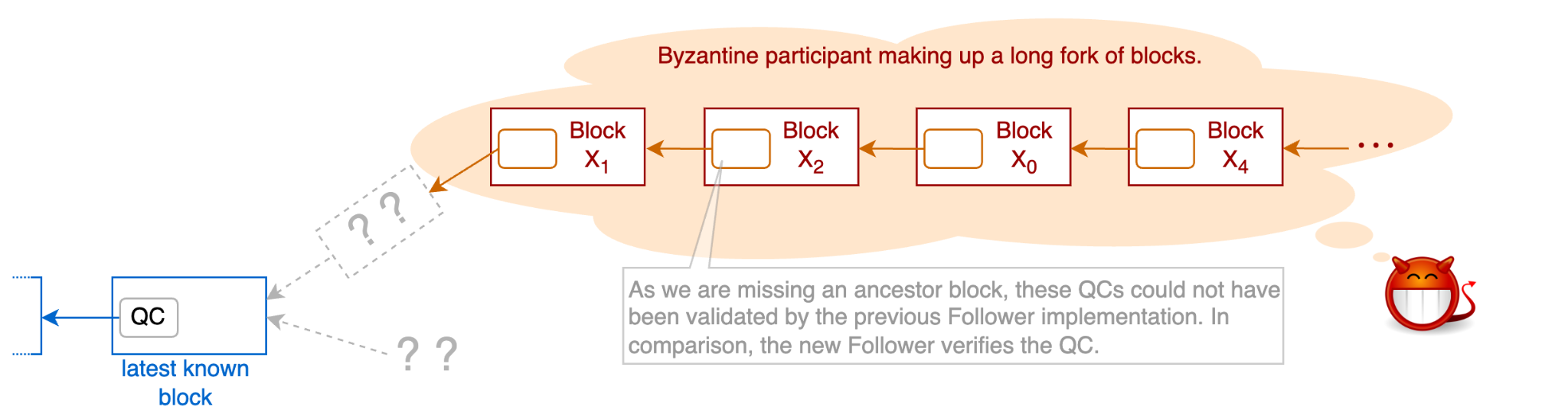
In the depicted example, Evil Edward — a Byzantine consensus participant — is making up a long fork of blocks. As these blocks are fake, they haven’t been voted on by the consensus committee and no valid QCs exist for them. Therefore, Edward includes invalid QCs in his fork. The previous Follower cannot assess whether the QCs in Edward’s fork are valid since the Follower does not know the full ancestry for the fork.
With enough blocks and time, this attack could cause the Follower to crash with an out of memory exception. Even without a crash, this memory exhaustion attack can harm the Follower by flooding its cache with fake blocks, which delay the processing of valid blocks. In tests, we have seen that mounting a memory exhaustion attack on a node’s Follower caused the node to fall behind and fail to fulfill its function within the network in a timely manner.
The upgraded Follower can now validate blocks within the current epoch (one week) before their ancestors are known. Therefore, the new consensus follower would detect Edward’s fake blocks as invalid, discard them and raise a slashing challenge against Edward. Blocks outside the current epoch are immediately discarded.
Cache / Storage Improvements
The Follower uses a cache to store blocks which have not yet been incorporated into the blockchain. This cache is now separated into distinct sections for certified and uncertified blocks.
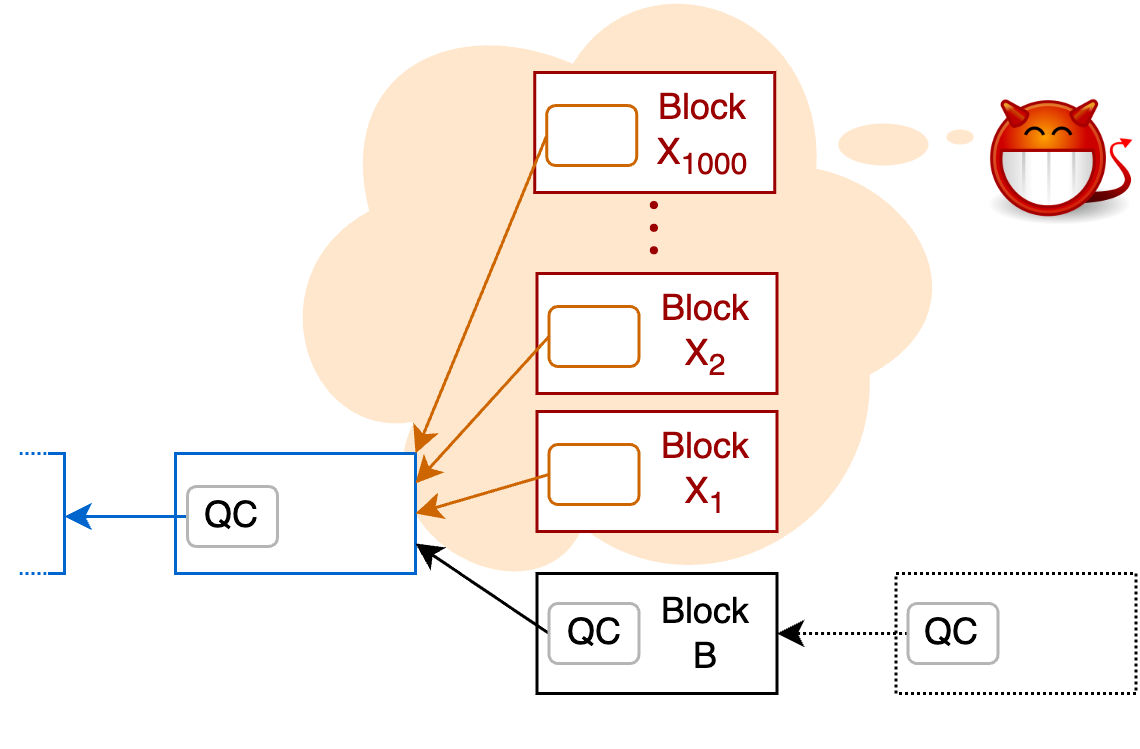
In the example above, the malicious primary has created 1,001 conflicting blocks. Consensus rules guarantee that only one of them will get certified (in our example block B). However, it is not clear in advance which one will eventually be certified to a Follower receiving the blocks. Therefore, the old Follower would store all blocks on disk, which is a vector for storage exhaustion attacks.
In comparison, the new Follower only stores certified blocks on disk. As only one of the many conflicting blocks can be certified, certified blocks pose little risk of storage exhaustion attacks.
Uncertified blocks have a valid proposer signature, but may nevertheless pose a threat in the case of a malicious leader. Therefore these blocks are stored separately in a size-limited cache which mitigates memory exhaustion attacks.
Parallel Validation
Flow's core consensus algorithm runs in a single-threaded event loop, meaning that one event is processed at a time. This is desirable for the simplicity of this mission-critical component, but limits performance.
A focus of recent architectural changes to Flow's consensus has been shifting work out of this event loop where possible. The team implemented parallel vote processing in early 2022, parallel timeout processing in the recent Jolteon upgrade, and we are extending this to include parallel QC validation in the Follower engine as part of Follower V2.
This change is particularly beneficial when a node which has fallen behind is catching up, because it can process more blocks in parallel.
Chained Validation
When a block is certified, a supermajority of Consensus Nodes have agreed that the block is a valid extension of the state and voted for it. As a blockchain where each block builds upon its parent, a block is only valid if it is extending a valid block. In other words, if a block is certified, then all its ancestors are certified, too.

The new Follower can leverage this fact to avoid unnecessary work. When processing a sequential range of blocks, it is sufficient to ensure that the block at the end of the range is certified (and to check that the block hashes match). Hence, we only perform one expensive signature validation operation for the entire batch, instead of one for every block in the batch.
When a node is catching up, it receives blocks in sequential ranges by default, and can make use of this validation improvement to improve syncing speed.
Laying the foundation for smartphone-sized light clients
When envisioning light clients running on embedded hardware, including smartphones, there are three main challenges to solve:
- The amount of CPU cycles, memory, and storage that a light client can reasonably consume is extremely limited. You probably prefer to use your smartphone storage for photos rather than gigabytes of chain data.
- For a light client to be useful to an average end user, it has to deal with being offline for prolonged periods of time. Even if the light client were allowed to validate chain progress constantly by the operating system and user behavior, doing so would deplete batteries unacceptably quickly.
- Lastly, the light client must be able to catch up on multiple days of chain progress quickly and efficiently. Downloading all blocks is not an option. Imagine returning from a three-day camping trip, eagerly trying to check whether the trades for some NBA Top Shot Moments have succeeded – but your phone takes 20 minutes to download and validate all the block headers it missed… and runs out of battery.
As discussed earlier in this article, the new Follower allows validating QCs for blocks without knowing their entire ancestry as long as those blocks are within a known epoch. For Flow, an epoch is typically one week long. Within this week, the set of authorized nodes remains unchanged. If a node is slashed, the network might revoke their right to propose blocks, but no new nodes are added mid epoch.
At the epoch transition, the nodes authorized to run Epoch N hand the control of the blockchain over to the nodes for Epoch N+1. Slightly simplified, this works as follows:

- At the beginning of Epoch N, new nodes can participate in the staking auction for Epoch N+1.
- At the end of the staking auction phase, an EpochSetup event is included in a block, which lists all authorized nodes for Epoch N+1. Thereafter, the nodes for Epoch N+1 collaboratively execute a distributed key generation (DKG) protocol during the Epoch Setup Phase. This important step allows Flow to be of very few blockchains to provide secure randomness natively within the protocol. The EpochCommit event is included in a block when the DKG ends.
- The EpochSetup and EpochCommit events together form the ‘Identity Table’ for Epoch N+1. In a nutshell, the Identity Table for Epoch X contains all information necessary (such as node identities, roles, public keys, etc) for validating QCs generated during Epoch X.
Note that any Follower that has the Identity table for Epoch N only needs a few blocks to construct the Identity Table for Epoch N+1. The figure below illustrates this process:
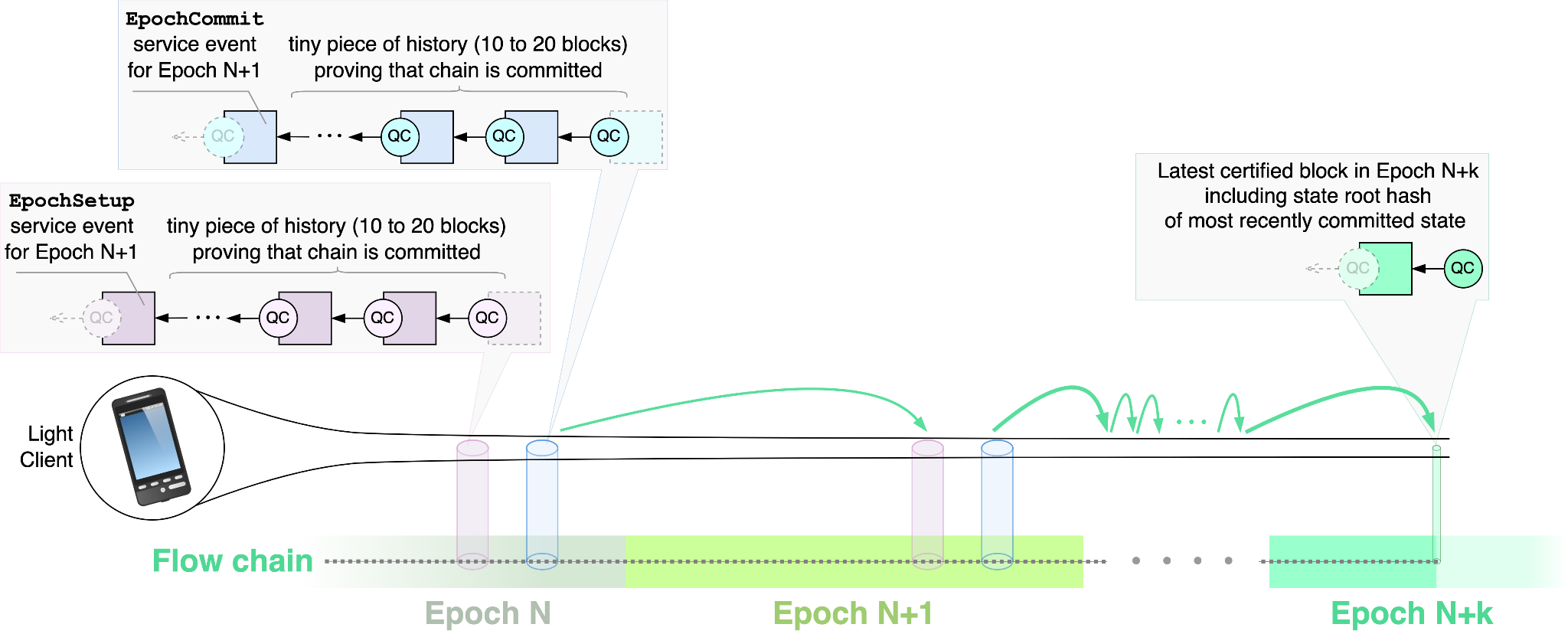
- The Follower simply contacts a full node and requests “the blocks containing the EpochSetup and EpochCommit events for Epoch N+1 plus sufficiently many child blocks proving that the EpochSetup and EpochCommit events were sealed.”
- The Follower, which knows the Identity Table for Epoch N, can assess the integrity of the response by checking the QCs and block hashes, because all the blocks it received must belong to Epoch N. If any check fails, the Follower knows it has received a corrupted response and discards it. However, if the checks pass, the Follower has cryptographic proof that the consensus committee of Epoch N committed the EpochSetup and EpochCommit events.
- At this point, the Follower knows the correct Identity Table for Epoch N+1 and can repeat the same process to retrieve the Identity Table for Epoch N+2 and subsequently N+3, etc.
In summary, the Consensus Follower only needs to retrieve two chain segments of 10-20 blocks each to locally construct the identity table for the following epoch. The validity of the blocks is asserted through validating the tailing QC at the end of each batch and re-hashing the received blocks.
While roughly 460,000 blocks are finalized during an epoch, a consensus Follower only needs to retrieve 0.005 percent of those blocks. Thereby, the Follower can fast-forward through months or even years of blocks consuming negligible computational and networking resources.
Furthermore, consider an Epoch (past or current) for which the Follower knows the identity table. The Follower can retrieve a short chain segment at any height belonging to the epoch and assert its validity and finality by checking the QCs. Hence, the Follower can trustlessly obtain the state root hash for nearly any block of the epoch, as state root hashes are also contained in the blocks [2]. When knowing the state root hash at some block, it becomes possible to selectively retrieve part of the state in a trustless manner utilizing Merkle proofs.
Notes
- [1] Collection nodes are a special case, because they operate as both Participants and Followers. They follow Flow's main consensus while participating in their cluster's sub-consensus protocol, which ingests a portion of transactions inbound to Flow. This separation of responsibilities is one of the innovations supporting Flow's scalable architecture.
- [2] We simplified the discussion here a little. In Flow, blocks don’t directly contain the state root hash obtained after executing the contained transactions. Instead, block execution is asynchronous in Flow, and execution results are embedded into descending blocks once they become available. If you want to learn more, we recommend this excellent blog series.
Interested in building on Flow? Visit our developer portal to get started, and keep in touch with us on Twitter or Discord.