

Major Upgrades to Flow Network: Smarter Storage, Faster Nodes, and Seamless Migrations

Flow is pushing the boundaries of blockchain efficiency and scalability. In February, a major enhancement called Account Storage Format v2 was introduced to further optimize state storage on Flow. The goal was to reduce memory usage on execution nodes, improving network state scalability while lowering costs and operational overhead for all nodes storing and serving on-chain data.
The impact? A 30% reduction in memory usage on execution nodes.
This article shows the results of that upgrade and introduces another significant advancement currently in progress—the migration to the Pebble database.
Let’s dive in.
Reducing Memory Usage by 30% with Optimized On-Chain State Storage
The Flow Crescendo release last year introduced a significant enhancement in how on-chain data is stored. In Crescendo, state storage was optimized through the Atree register inlining technique resulting in 38% reduction in memory usage on the execution nodes. After that release, additional opportunities for optimization were identified to further refine state storage.
These optimizations, termed as Account Storage Format v2 were implemented and released through a network upgrade last month.
You can read more about the upgrade here - https://github.com/onflow/flow-go/releases/tag/v0.38.2.
A standout aspect of this upgrade was Flow's first-ever "on-the-fly" data migration, which allowed the state storage changes to be deployed without any network downtime. Typically, storage migrations require hours of network downtime as the state is converted from one format to another and such downtime can be highly disruptive to stakeholders. However, this migration occurred while the network was running through an ambient background process—a first for Flow!
Results of Account Storage v2
Since the upgrade in February, state storage has a major enhancement, and the results speak for themselves:
✅ Memory usage on execution nodes dropped by 30% – shrinking from ~1 TB to under 700 GBs.
- The graph below illustrates memory usage on the execution node. The rollout of the new storage began on February 18 and was completed by February 22.
- (Execution-001 and 002 are Foundation-run execution nodes. Execution nodes operated by other participants would see similar improvements.)
.png)
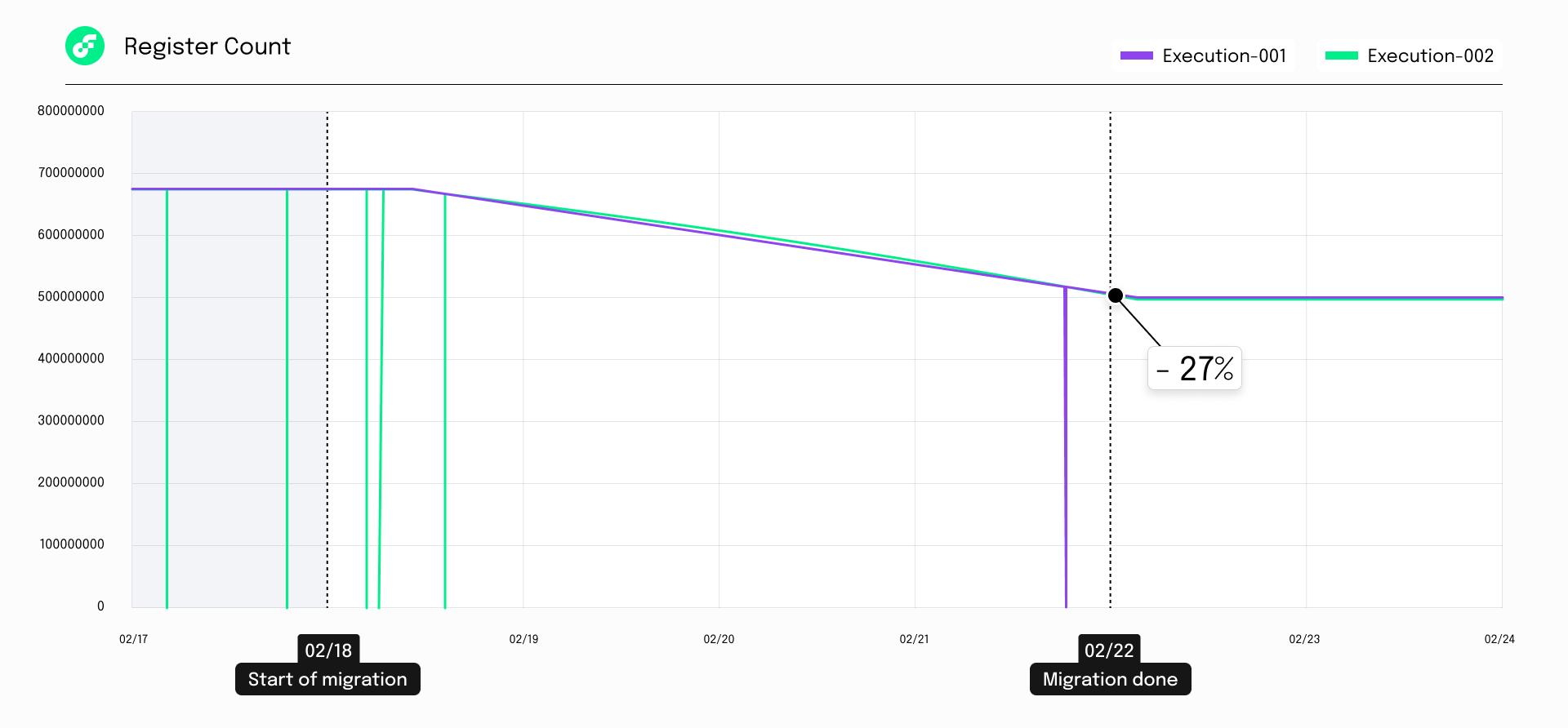
✅ The on-chain state register count decreased by ~27%, improving data access speeds.
- Zooming in a little bit more, the storage reduction was realized through the reduction in the number of registers which store the on-chain state.
- The following graph shows the decrease in register count with the deployment of the new storage.
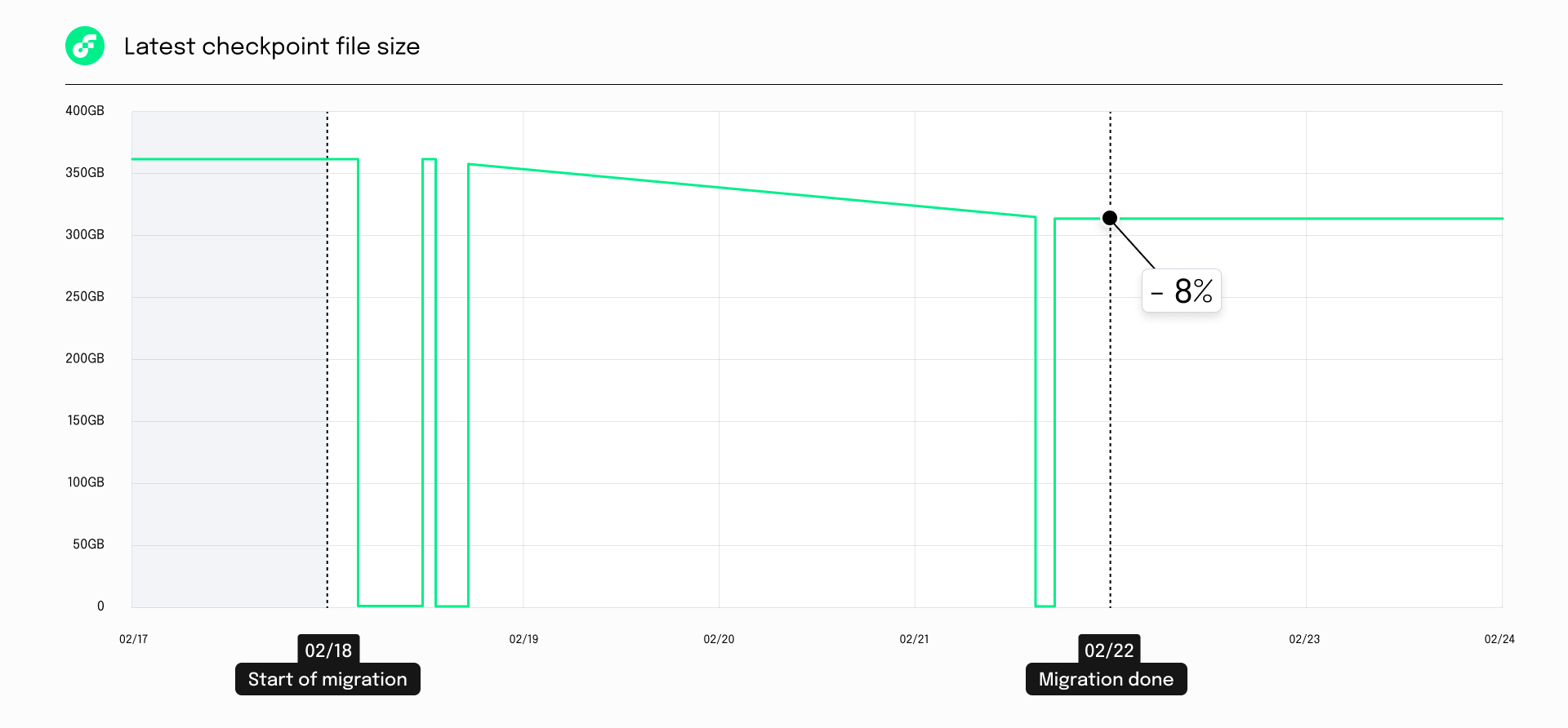
✅ Serialized state data stored on disk as checkpoint files was reduced by 8% – from 353GB to 226GB.
- Checkpoint files record state snapshot at regular intervals. The files are read by nodes serving execution data such as execution node, and access nodes when booting up. Smaller checkpoint files resulted in faster node bootup.
- Following graph shows the reduction in the checkpoint file size on a single execution node.
What’s next?
Goodbye, BadgerDB – Hello, PebbleDB!
Another major upgrade that is being worked on is the migration of database used by all Flow nodes from BadgerDB to PebbleDB.
For the past year, node operators have been encountering performance issues that can be directly attributed to BadgerDB. These include:
🔴 Unpredictable memory spikes – BadgerDB intermittently runs a data compaction process. This process causes large spikes in memory usage, sometimes resulting in the node running out of memory.
🔴 Lack of automated pruning – BadgerDB doesn’t support automatic data pruning, which means the database continues to grow in perpetuity and requires manual intervention by the node operator to free up space.
To solve this, Flow developers have been working on migrating Flow’s database storage to PebbleDB since late last year as it addresses all above mentioned issues and more. The first version of the execution node that uses PebbleDB has already been successfully tested on Flow Testnet!
Here is a graph of the execution node on testnet running Pebble DB after 2/22 showing how automated pruning resets memory usage on the node without any manual intervention.
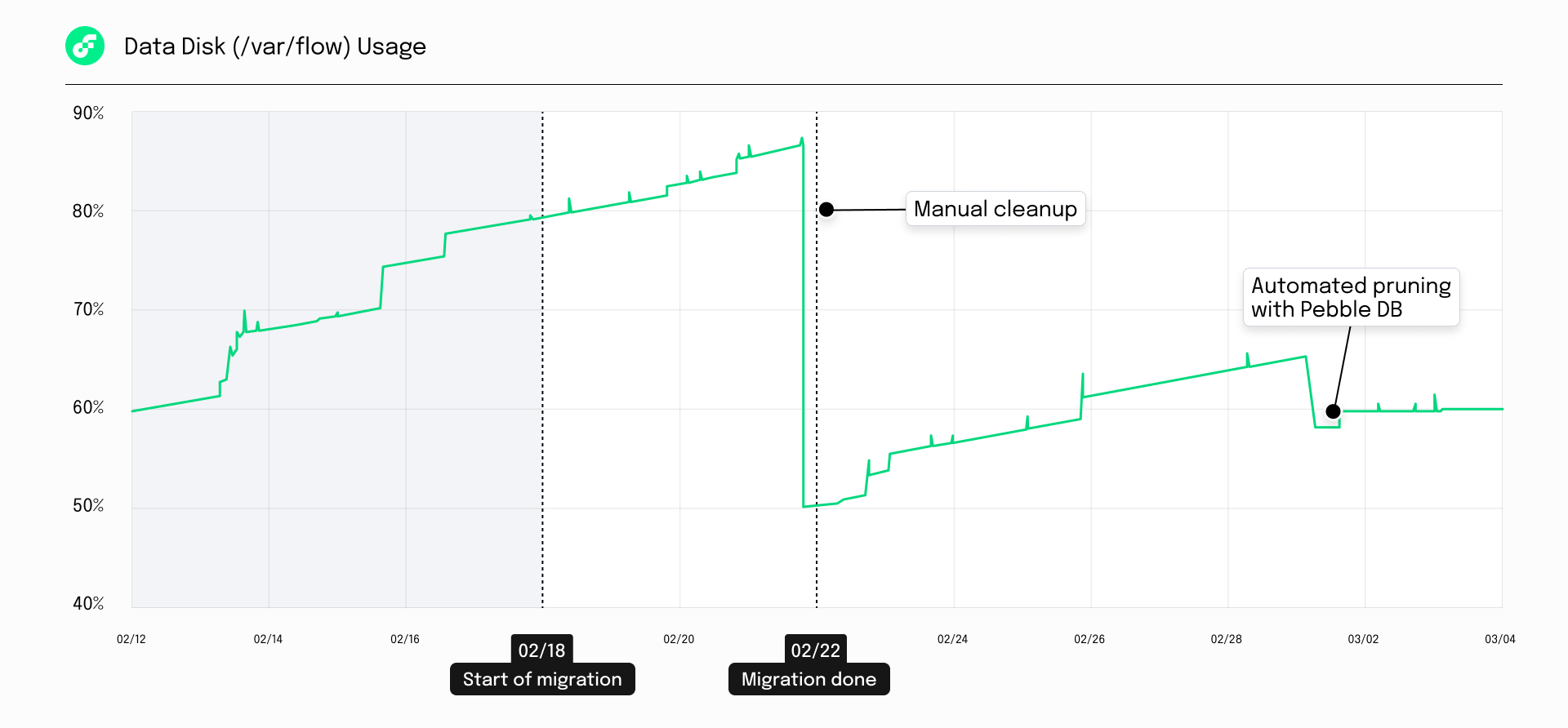
In summary, PebbleDB enables the following:
✅ Automatic data pruning – Storage on the node software can now be configured to retain only a certain amount of data and automatically remove older, unnecessary data.
✅ Lower operational overhead – Node operators no longer have to manually intervene to manage database storage - a current problem faced by node operators from time to time.
✅ Reduced memory usage – PebbleDB helps reduce overall memory consumption, further improving network stability by reducing the risk of nodes going out-of-memory.
✅ Reduced disk space – The automated data pruning means that nodes will require smaller disks.
What This Means
These upgrades aren’t just technical wins — they represent a foundational leap forward in how Flow handles blockchain state, and why that matters for the long-term health of the network.
Most blockchains today are struggling with state bloat — the ever-growing size of on-chain data that eventually slows down networks, increases costs, and drives complexity for developers. Many resort to Layer 2s or off-chain solutions to deal with this. Flow is taking a different approach: solving the problem at the protocol level, not offloading it to apps or infrastructure workarounds.
With these upgrades:
- Flow is scaling toward petabytes of on-chain state — something few other blockchains are even attempting, let alone optimizing for this early. By reducing memory and disk usage on core nodes, Flow is laying the groundwork to scale sustainably.
- Lower memory and disk requirements reduce operational costs — which makes it easier for more participants to run nodes, increasing decentralization and network security.
- Fewer memory spikes, fewer crashes — execution nodes now run more predictably and efficiently. That means more stability for developers relying on consistent read/write performance.


