

Inside Flow: The Multi-Node Architecture that Scales to Millions

Background: Flow is a new blockchain originally designed and developed by Dapper Labs, the makers of CryptoKitties and NBA Top Shot. In this multi-part series, we will explore the different components of Flow blockchain from a technical perspective.
• Cadence, the new programming language that makes smart contract development faster, safer
• Flow Client Library (FCL), it is analogous to Web3.js on Ethereum, but built for the consumer audience in mind
• Flow multi-node architecture, future-proof scaling for the mainstream adoption
Blockchain mass-adoption is well underway, and the success of applications like NBA Top Shot are just one testimony for this promising development. Large audiences of consumers are waking up to the potential the technology yields, and whole communities around brands, developers, creators, stars and fans are onboarding to decentralised applications every day.
For the blockchain protocols that power these applications, however, this ever-growing load of transactions poses a huge challenge: Scalability is the make-or-break moment for the blockchain industry as a whole — only if networks can scale to millions by default, will millions come. How the scalability issue is answered inevitably shapes the role that blockchain will play for a mass-audience of consumers.
The vast majority of projects currently relies on two solutions for this quest for consumer-grade scalability: Sharding (Layer 1) and rollups (Layer 2). These answers might tackle the immediate technical needs, but as we’ll explore later, they introduce greater risks, minimise the benefits of decentralisation and add complexity for developers and end-users in the long term.
By introducing the paradigm of pipelining, Flow proposes a solution that is more scalable, more decentralised and more secure than existing scaling solutions, without increasing complexity for developers or needing to rely on off-chain workarounds: Specialised node types. Rather than each node having to do all the work, Flow’s nodes are specialised along a transaction pipeline.
Collection nodes batch the work, consensus nodes secure the work, execution nodes do the work and verification nodes check the work.
This enables a multi-node architecture that
- Scales to millions by default by providing a highly performant base layer
- Makes network participation more accessible by lowering requirements for certain node types , they can even be run on consumer-grade laptops
- Increases decentralisation by lowering the barrier of running a node, which increases the likelihood of more nodes participating
- Abstracts complexity into the protocol to preserve ease of development, letting developers ship applications faster without needing to worry about infrastructure requirements
- Ensures great end-user experience by avoiding Layer 2 solutions, freeing users from needing to consider technical implication and keeping onboarding simple
- Preserves security at scale, since no transaction has to rely on potentially corrupt off-chain computations and all interactions between entities can happen in one atomic, consistent, isolated, and durable (ACID) transaction
This article will provide a short refresher on the basics before analysing the issues with existing scaling solutions, while contrasting how Flow’s new paradigm of pipelining specialised node types circumvents these limitations.
Basics revisited: The scalability trilemma
Real-world value can only be taken reliably to the digital sphere if data integrity and security is guaranteed. Centralised parties corrupt this guarantee willingly or unwillingly, either by pursuing malicious behaviour themselves or by posing a single point of failure in case of outside attacks. Think about it: If only one corporation manages a user’s account balance, nothing could stop an employee of this organisation from tampering with it or accidentally deleting it. There is no safety mechanism in place that reaches beyond the organisation as a central party.
The integrity of data can only be assured if a system of checks and balances is in place, and this is precisely what blockchain technology offers. The main advantage of a blockchain network is that it provides high degrees of decentralisation, describing a network that consists of various individual nodes that jointly manage a shared state: Account balances, smart contract code, data structures, and much more.
Transactions are algorithms that mutate that state, or, put simply, transactions resemble user-initiated actions that handle value, identity, or other critical processes. The decentralised nodes agree on what transactions are valid, and which are not — they find consensus and punish malicious nodes.
Every blockchain that supports Turing-completeness, i.e. the ability to run any kind of computation, has one major vulnerability: the possibility of someone spamming the network with never-ending computations. Also, since most networks are publicly available, blockchains represent a public good, and as the tragedy of the commons describes, this often leads to few ruthless actors exploiting this good, possibly ending in harmful over-consumption or depletion of the resource itself - just think about our environment in this context.
To prevent these Denial-of-Service attacks and limit overuse, networks like Ethereum have introduced a transaction fee: gas. Gas makes DoS attacks economically highly unfeasible, because a transaction needs to be provided with an amount of gas that increases with the complexity of the transaction.

When a user sends a transaction with the due amount of gas to the network, these transactions are formed into a block — chunks of transactions that are validated as a unit. Each block has a certain gas limit, so there is a cap on the number of operations within a block.
But why limit the throughput? When the gas limit is not capped at all, potentially immense amounts of data could be added or mutated in a short amount of time. Whenever a new node joins the network, it has to gather all this data , and this amount of data might be enormously high without a block gas limit in place, increasing the time and hardware requirements needed to set up a node. Already now, with tight block gas limits in place, it takes about 17 hours to set up a full Ethereum node.
The increased hardware requirements make it infeasible for an individual to set up their own node — but the security and resiliency of a blockchain network against sybil attacks is directly tied to the number of individual nodes, and less nodes means a higher degree of centralisation, introducing higher security risks.
"For a blockchain to be decentralized, it’s crucially important for regular users to be able to run a node, and to have a culture where running nodes is a common activity."
— Vitalik Buterin in The Limits to Blockchain Scalability
These observations precisely render the edges of what we call the scalability trilemma, meaning that blockchain networks can only be sufficiently performant in two of the following three dimensions: scalability, security, decentralisation.
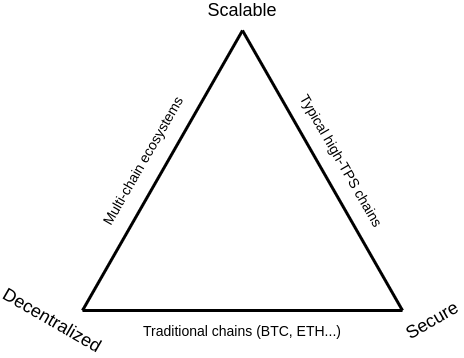
The quest for blockchain scalability always involves the challenge of trying to overcome these limitations and break out of this triangle. In Ethereum’s case, Vitalik Buterin describes one solution to leave these limitations behind: Sharding.
Sharding: The good, the bad and the ugly
The idea of sharding is nothing specific to blockchain — database systems commonly use this type of horizontal scaling. The main thought behind this strategy is to split up the state of a blockchain into multiple smaller chunks and distribute them across nodes. The state is thus spread across multiple individual shard chains, while a central beacon chain takes care of coordinating and orchestrating these shard chains.
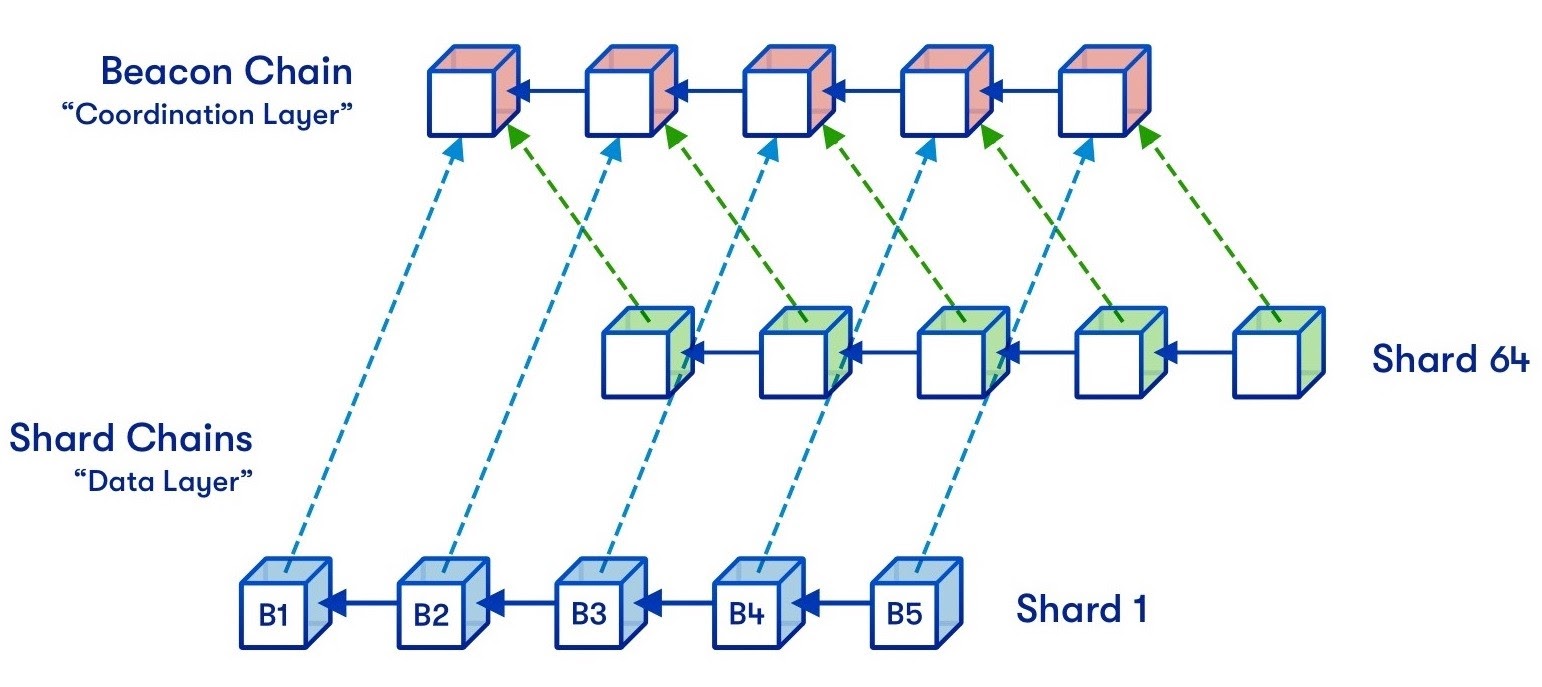
In the case of sharding, each node has to take care of two things: keeping track of one particular shard-chain and also following the main beacon chain. This requirement introduces a hard limit on how far sharding can increase scalability: If shards are too big, nodes can no longer process individual shards, and if there are too many shards, nodes can no longer process the beacon chain.
Precisely due to this reason, Vitalik Buterin has stated that only a combination of sharding with other scaling strategies - especially layer 2 solutions like rollups - will guarantee a sufficient level of throughput in the long term. In light of the enormous complexity that the implementation of sharding demands (as can be seen by looking at Ethereum’s cumbersome road to ETH 2.0), this is a quite sobering thought on the efficiency of sharding, especially when considering that it introduces new risks for a network.
One of these risks is the requirement of a minimum number of participants. A non-sharded blockchain can always run as long as there is only one active node, but in a sharded blockchain network no single node can manage all the state of the blockchain alone. Vitalik Buterin gives a more detailed overview of this problem in this blog post, but essentially the risk lies in a sudden drop of network participants (due to outages or coordinated malicious behaviour) below this threshold — in such a case, the integrity of the whole network is in danger.
But the main problem of sharding lies beyond these limits and risks: The reason why Flow has decided against sharding as a solution to the scalability problem is that sharding introduces additional overhead, complexity and impedes ACID-compliant transactions and composability.
To understand this point, it’s important to keep in mind that one of the great catalysts of innovation is composability: The idea that an application can build on top of an already existing application, or use some of its functionality. One common use case is the import of standardised interfaces (e.g. ERC-20) from other contracts, freeing developers from re-inventing the wheel over and over again; or the trading of fungible tokens across multiple smart contracts.
In a non-sharded blockchain, these interactions across different smart contracts are straightforward, since they all live in one single state space. A transaction can easily be atomic, consistent, isolated and durable (ACID).
On a sharded blockchain however, the external smart contract called might live in another state-space, on another shard, requiring complex lockup or escrow schemes because information on any particular shard may change before the transaction ends. What used to be one single, simple, transaction can balloon into ten or twenty cross-shard interactions, with each of these transactions running fragile asynchronous code. At the same time, cross-shard communication introduces additional latency that might nullify the added throughput of the scalability effect in the first place.
This shows that sharding increases complexity for application developers, impacts user experience and makes ACID-compliant transactions hard to implement. In a place that’s all about value and where confidence about the outcome of a transaction is key, this poses a huge anti-pattern, just like the use of arbitrarily mutable data structures for digital assets of value. Because of these limitations, risks and anti-patterns introduced, sharding is not the ideal solution to scale blockchain networks to mass global adoption.
The problems with rollups
Rollups are part of a more general scalability strategy grouped under the broader term of layer 2 solutions. The philosophy behind all layer 2 solutions is to increase the throughput of a blockchain network by running computations off-chain (off of the main chain, that is), actively decreasing load on the actual protocol (layer 1) and only commit crucial state updates to it in regular intervals.
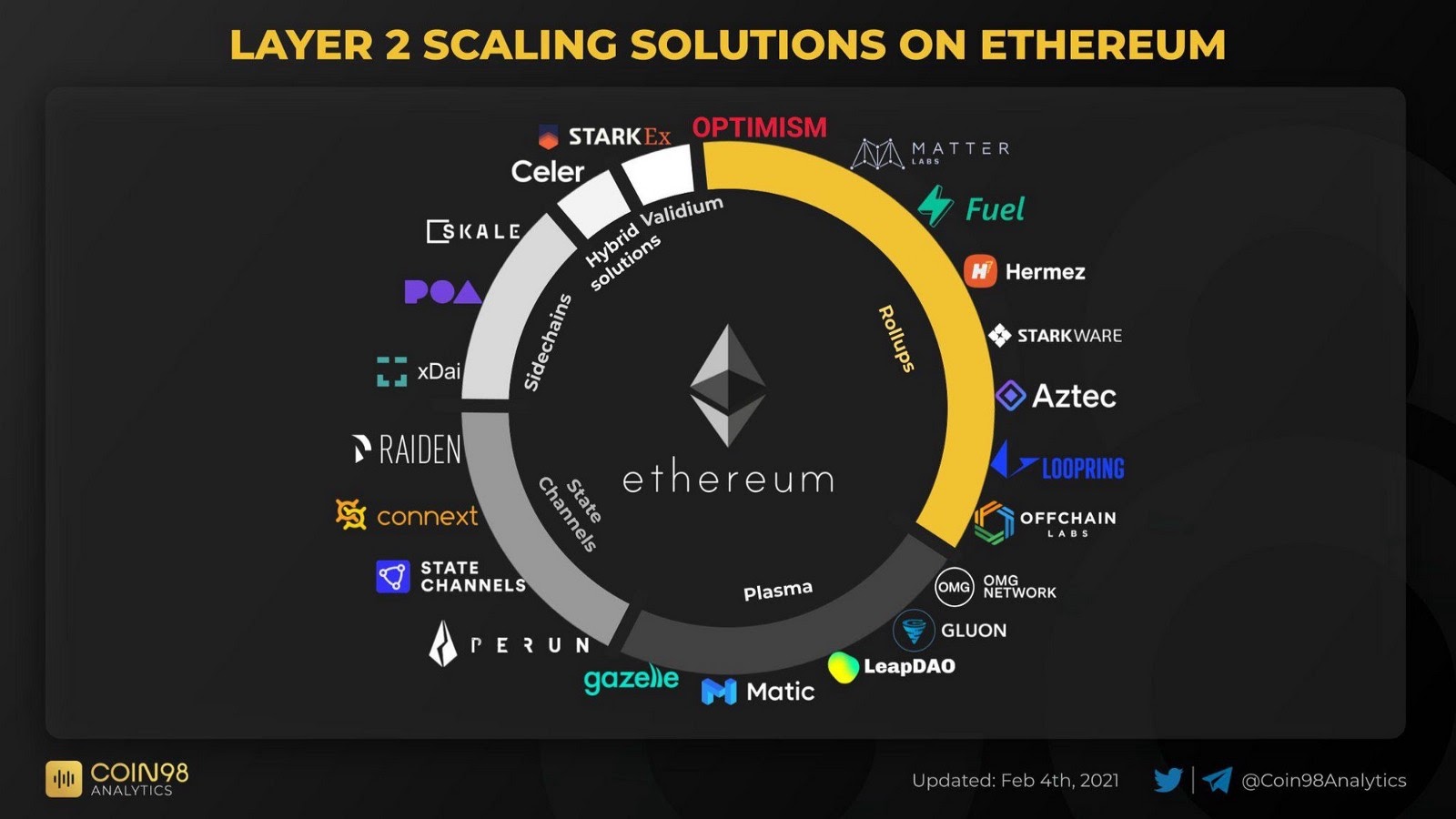
Besides rollups, there are also the layer 2 concepts of state channels, plasmas, sidechains and some hybrid solutions that combine various ideas of these types. This article focuses mostly on rollups, since they are the most recent and most promising development in the overall space of layer 2 solutions.
Rollups, like all layer 2 solutions, have one big challenge to tackle: How can transactions be secured off-chain, and how can their integrity be validated when committing back to the base chain?
Optimistic rollups try to achieve this by heavily relying on game-theory: When the off-chain transactions are committed back to the main chain, anyone can challenge the outcomes of these transactions before they are finally committed; zk-rollups rely on complex mathematical proofs known as zero-knowledge proofs, which implicitly guarantee the integrity of the computations. The inner workings of both are highly non-trivial and fairly hard to grasp —Vitalik Buterin’s “An Incomplete Guide to Rollups” is a great starting point for those longing for more in-depth details.
Rollups are a new phenomenon, and the foundation they are built on is — especially in the case of zk-rollups — a whole field still needing to be explored and defined. This observation renders the first problem with rollups in general: Taking transactions from the secure environment of the main chain and relying on mechanisms that still need to be battle-tested at large scale introduces great technological risks for assets deployed on these solutions.
"It’s new technology, it’s crazy technology, it’s admittedly scary technology."
—Vitalik Buterin on zero knowledge proofs
And while they do certainly help to enable high throughput paired with low transaction fees, rollups dramatically increase the engineering overhead and introduce complexity for developers and end-users alike, possibly nullifying the technical scalability factors in the long-term. y
There’s a variety of layer 2 solutions out there, and developers have to actively change their codebase for every single layer 2 solution they want their application to support. These changes are not merely done by adding a few lines of code — most zk-rollups require developers to learn a special programming language (e.g. Cairo for StarkWare or Zinc for zkSync) and deploy separate versions of the application’s smart contracts in that language. Learning those languages or finding talent for these niche topics is a lengthy process that has to be repeated for every new solution supported.
This added complexity in development does not only increase the time to market and the possibility of fatal errors, but also inevitably spills over to end-users, since they need to be actively aware of the technicalities: Only if they research on which layer 2 solution their favourite application is deployed, they can start using it.
Furthermore, layer 2 solutions add an additional step to the onboarding process, increasing the friction and excluding users who are less tech-savvy. For example, in order to use solutions on zkSync, users not only have to first set up and fund an account on Ethereum, but then also commit an amount to zkSync’s wallet; this process repeats in reverse when wanting to withdraw funds.
Speaking of layer 2 off-ramps: in the case of optimistic rollups, users need to wait a certain amount of time (in most cases approximately one week) before they can access their withdrawn funds — this limit is imposed by the challenging-mechanism of optimistic rollups. In a fast-paced environment where users expect actions to resolve immediately, this is a huge blocker for mass-adoption of these solutions.
In summary, layer 2 results in a fragmented ecosystem whose complexity is pushed to an almost unmanageable degree, vastly increasing the time and resources both engineers and end-users have to invest in order to build or use blockchain-enabled applications— it’s an avenue that promotes the exact opposite of what is needed for blockchain mass adoption. In order to provide great scalability in combination with good user experience, ease-of-development and security, a fundamental paradigm shift is inevitable.
Enter: Flow’s multi-node architecture.
Flow’s new paradigm: Pipelining with specialised node types
Flow’s multi-node architecture provides higher levels of throughput and decentralisation than existing solutions, while preserving ease of development, user experience and digital asset security — without relying on sharding or layer 2 solutions. These features needed a fundamental change in the architectural paradigm of the protocol: Instead of horizontal scaling, Flow leverages vertical division of labor, a process also referred to as pipelining.
Pipelining builds on the same idea that Henry Ford had in the early years of the nineteenth century at his automobile plant at Highland Park, inventing a concept that laid the foundation of global consumer-scale production: Fordism. It’s secret to success was the division of labor along a standardised pipeline — when one worker didn’t have to assemble all parts of an automobile, but rather only focus on one specific task, they could specialise deeply and the requirements that this worker had to bring to the table significantly dropped.
In this analogy, networks like Ethereum operate as if one worker was to build an entire car: Every node has to do the combined labor of consensus and computation. In this regard, sharding is merely an illusion of divisional labor: While every node has only to compute a part of the shared state, they are still responsible for each running every single computation of this block and participating in consensus.
Flow’s multi-node architecture, in contrast, can be thought of as a pipeline that allows high degrees of specialisation for each individual node type, each focussing on one specific task — jointly, this pipeline can overcome the trilemma of scalability.
Each transaction that is sent to the network via an access node is first put into batches, so called collections, by collector nodes. These collector nodes are responsible for data availability; each well-formed transaction is stored on one of these collector nodes until it is included into a block.
Collections are formed into blocks by consensus nodes. These nodes take on the subjective task of ordering transactions. While arguably being the most important node type in regards to protocol security, this node type is particularly light on resource usage. Because they only request the transaction IDs from collector nodes — and not the whole code of the transaction — data throughput requirements can be held to a minimum.
Execution nodes request the full transaction code from the collector nodes after finding out from the consensus nodes which block to run next. These nodes are the most highly scaled of all node types and are dedicated to running the computations of the block as fast as possible. The smaller number of nodes decreases the redundancy of work, speeding up the time of these computations. Because they are closely looked after by verification nodes, this smaller number has no effect on the overall decentralisation of the protocol as a whole. Also, fewer high-performance nodes means less energy consumed, and thus less harm done to the environment.
Verification nodes are the watchful eye that closely observes every step of the execution nodes. After the subjective task of ordering the transactions (consensus nodes), the transactions themselves are deterministic and their outcome can be objectively known. Each of the many verification nodes now assesses one sub-part of the overall block computations. If one step is leading to a wrong result, the verification node triggers an alarm, possibly initialising a slashing challenge (the process where harmful nodes are deducted a certain amount of their stake). Just like the consensus nodes, the hardware requirements for verification are moderate, motivating users to run their own node.
After the computational results of the execution nodes have been thoroughly checked by the verification nodes, the block is sealed by a consensus node. At this point in time, one can be confident in the outcome of a transaction that was included in the block.
Just like the separation of power in democratic republics, execution nodes, consensus nodes and verification nodes create a system of checks and balances, where the few high scale execution nodes are closely observed by a large number of verification nodes, while consensus nodes seal the final transaction.
In essence, Flow’s specialised node types greatly increase the motivation of network participants to run a node due to lower hardware requirements, thus increasing decentralisation and security of the whole network. This makes participation in blockchain network more accessible and less resource intensive, while still having few performant machines to execute computations as fast as possible — all while keeping the complexity abstracted into the protocol. This means that good end-user experience is preserved while developers can focus on shipping their application fast.
Flow’s multi-node architecture is the blueprint for future-proof, consumer-scale blockchain protocols.
Further readings


