

Migrating Flow Node Storage from BadgerDB to PebbleDB

For years, Flow nodes have relied on BadgerDB as their on-disk key-value storage engine. As the network grew and usage patterns evolved, we began facing limitations with BadgerDB in terms of performance, maintenance, and operational overhead. To address these challenges, we recently migrated Flow’s node storage backend to PebbleDB, a modern RocksDB-inspired Go-based storage engine. This upgrade promises improved stability, better resource efficiency, and easier maintenance for node operators.
In this post, we’ll explain why we decided to switch from BadgerDB to PebbleDB, how we carried out the migration safely, and the results we’ve observed since making the change.
Why Switch from BadgerDB to PebbleDB?
Several factors motivated the move away from BadgerDB to PebbleDB:
- Lack of Maintenance in BadgerDB: BadgerDB is no longer actively maintained, raising concerns that future updates to Go or new hardware could leave us stuck on an outdated storage engine. PebbleDB, by contrast, has broad adoption and ongoing development, ensuring it stays compatible with the latest systems and receives continuous improvements.
- Unpredictable Memory and I/O Spikes: BadgerDB’s internal compaction process can trigger large spikes in memory, CPU, and disk I/O usage. These unpredictable surges have caused nodes to run out of memory in the past. As the data grows, such issues are likely to reoccur more frequently. PebbleDB offers higher stability under large load and avoids these dramatic compaction spikes, resulting in smoother node operation.
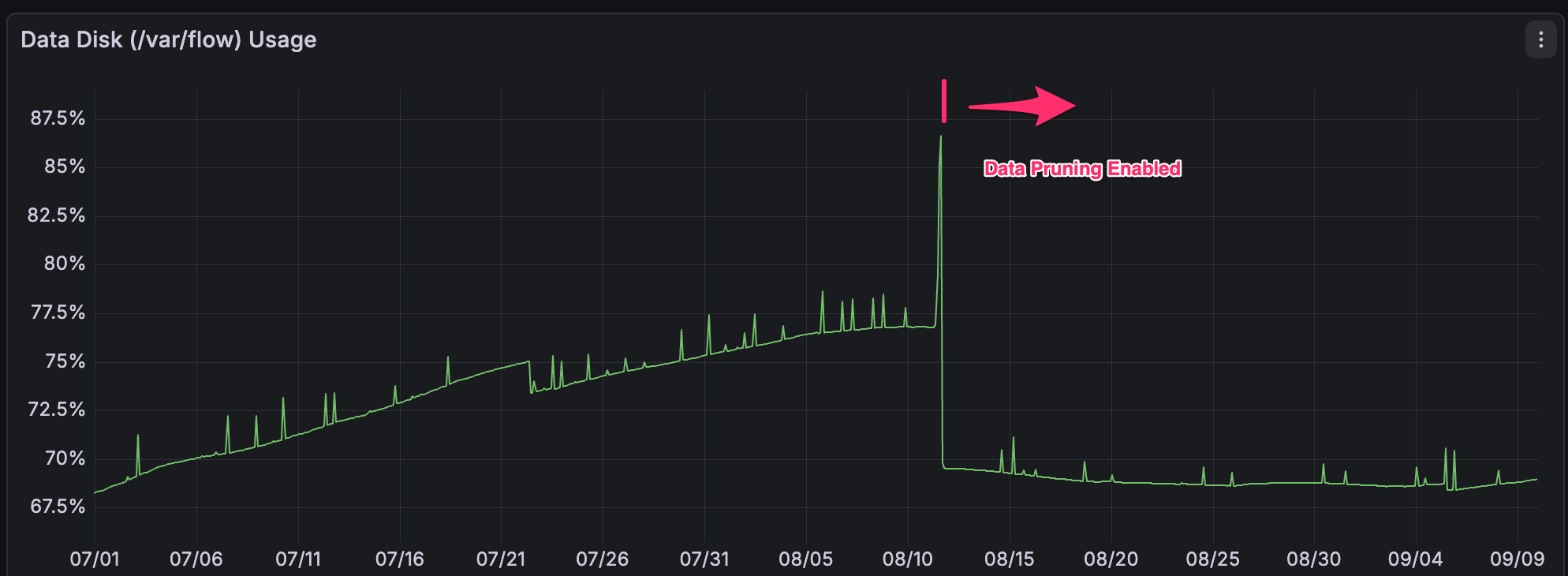
- No Automatic Data Pruning: BadgerDB lacks built-in support for automatically pruning old data (at least our testing showed that removing entries does not effectively reclaim disk space for our workloads). This means a node’s database will grow indefinitely unless an operator manually intervenes (often taking the node offline) to delete or compact stale data. PebbleDB, on the other hand, supports automatic pruning of historical data, allowing the node to continuously reclaim space without downtime.
- Data Compression: BadgerDB includes an option for value compression, but in practice we found that it did not reduce on-disk size for our workloads. Internally, we created test cases to verify this behavior, and observed that enabling BadgerDB’s compression produced no meaningful reduction in stored data size.
PebbleDB, on the other hand, applies effective block-level compression by default. Compression reduces the rate of disk usage growth, meaning nodes consume storage more slowly over time. This helps keep disk footprints manageable and lowers costs for node operators.
How We Migrated to PebbleDB
Switching the database engine of a live blockchain node is a complex endeavor. We approached the migration carefully to ensure correctness and minimize disruption:
- Lock-based correctness and race-condition prevention:
Unlike BadgerDB, which offers full ACID transactions, PebbleDB provides only atomic batch writes. To ensure the same correctness guarantees, we needed a different way to coordinate concurrent reads and writes safely. PebbleDB ensures atomicity only within a batch, so we implemented a lock-based strategy that prevents other threads from reading partial state while a batch is in progress. This guarantees that related updates are applied consistently and never observed halfway through.
However, batch operations often call multiple nested helpers, sometimes spread across multiple packages. Since the lock can only be acquired once, these helpers could independently verify that the required lock was held. Existing Go lock libraries couldn’t solve this because they don’t support querying whether a lock is held.
To address this, we built a lightweight context-aware lock mechanism. The lock is acquired once at the start of a batch, propagated through the context, and lower-level calls can verify that the required lock was acquired prior to performing a concurrency-sensitive operation. This avoids deadlocks, preserves atomicity, and keeps the storage layer composable.
This approach ensures safe concurrency without blocking unrelated operations, allowing the node to continue making forward progress even under heavy load.
- Abstracted Storage Interface: We refactored Flow’s storage layer to use a generic interface decoupled from any specific database. In other words, we defined common APIs for database operations (get, set, iterate, etc.) and provided two implementations underneath: one for BadgerDB and one for PebbleDB. This abstraction allowed us to swap out the database backend by simply configuring which implementation to use, without changing the higher-level business logic. As part of this transition, we also updated the BadgerDB implementation to use a lower isolation level that matched PebbleDB’s read-committed batch semantics, ensuring consistent behavior across both backends before the final migration.
This modular approach made the transition smoother and also future-proofs the node software to support other storage engines if needed.
Throughout the migration, we tested extensively on testnets and behind feature flags to ensure our new PebbleDB-powered backend matched BadgerDB’s behavior. We also provided tools for automatically migrating existing on-disk data from BadgerDB to PebbleDB format during a node upgrade, so operators could transition without manual interventions or lengthy downtime.
Results and Benefits
After migrating to PebbleDB, the improvements have been significant:
- Slower Data Growth & Smaller Disk Usage: Thanks to compression and automated pruning, nodes now reclaim space continuously, and annual disk consumption is roughly 40% lower than before. In practical terms, node operators can use smaller disks and configure their nodes to clean up old data on the fly if they want to only retain a limited blockchain history.
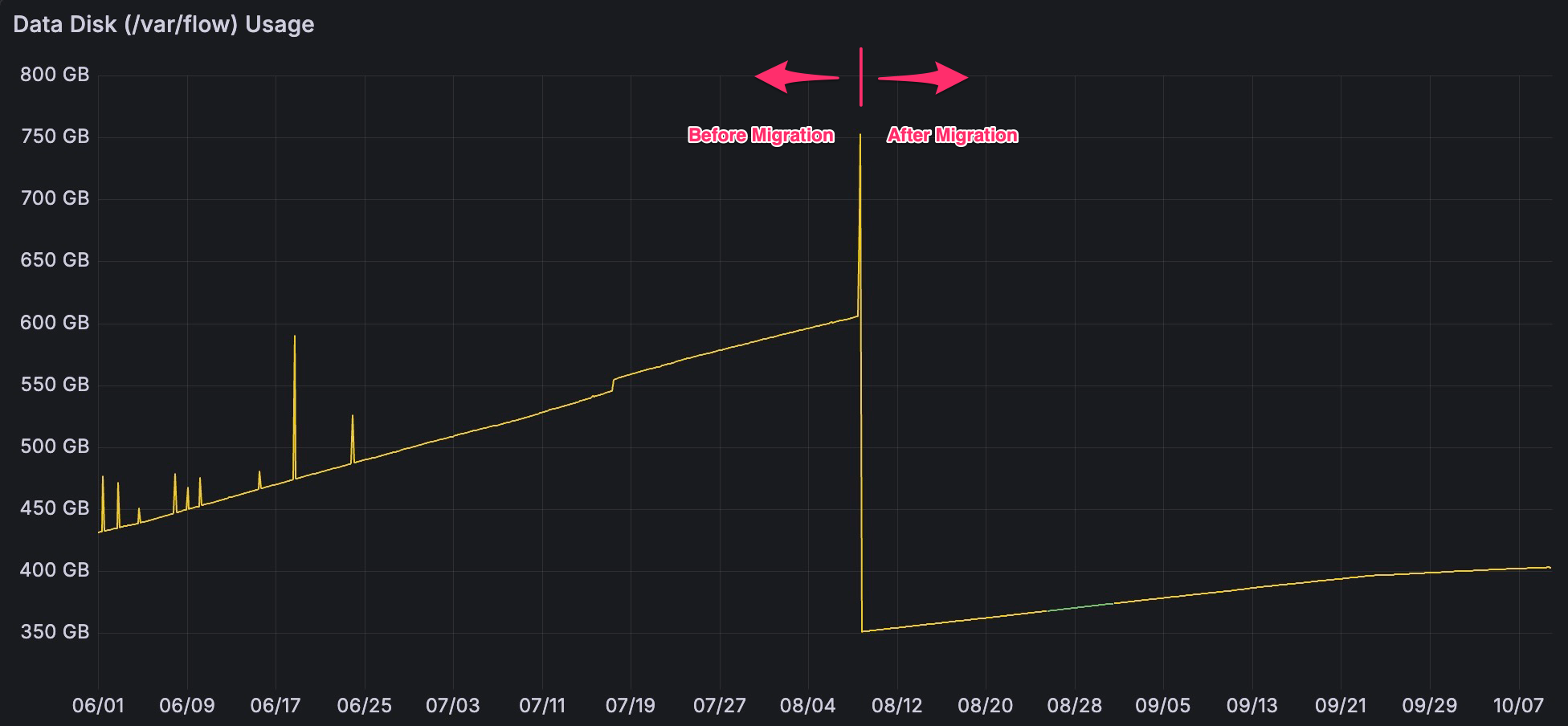
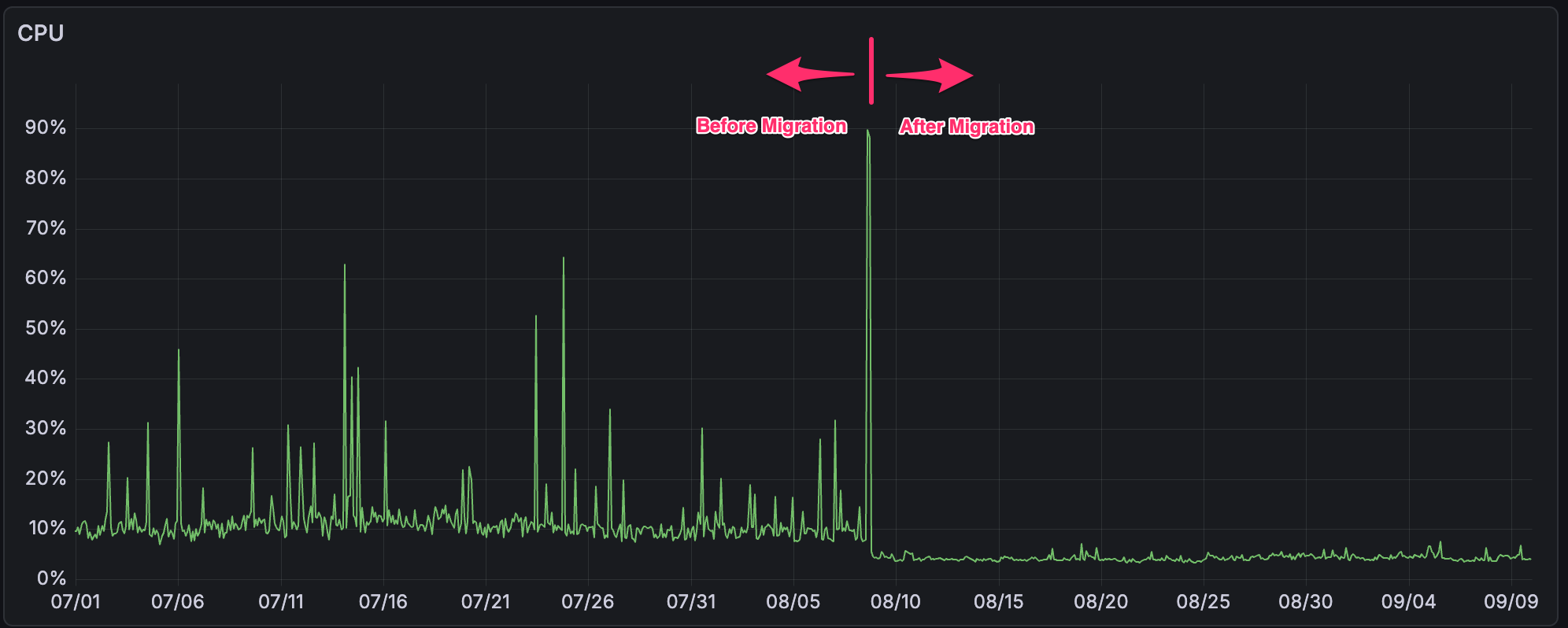
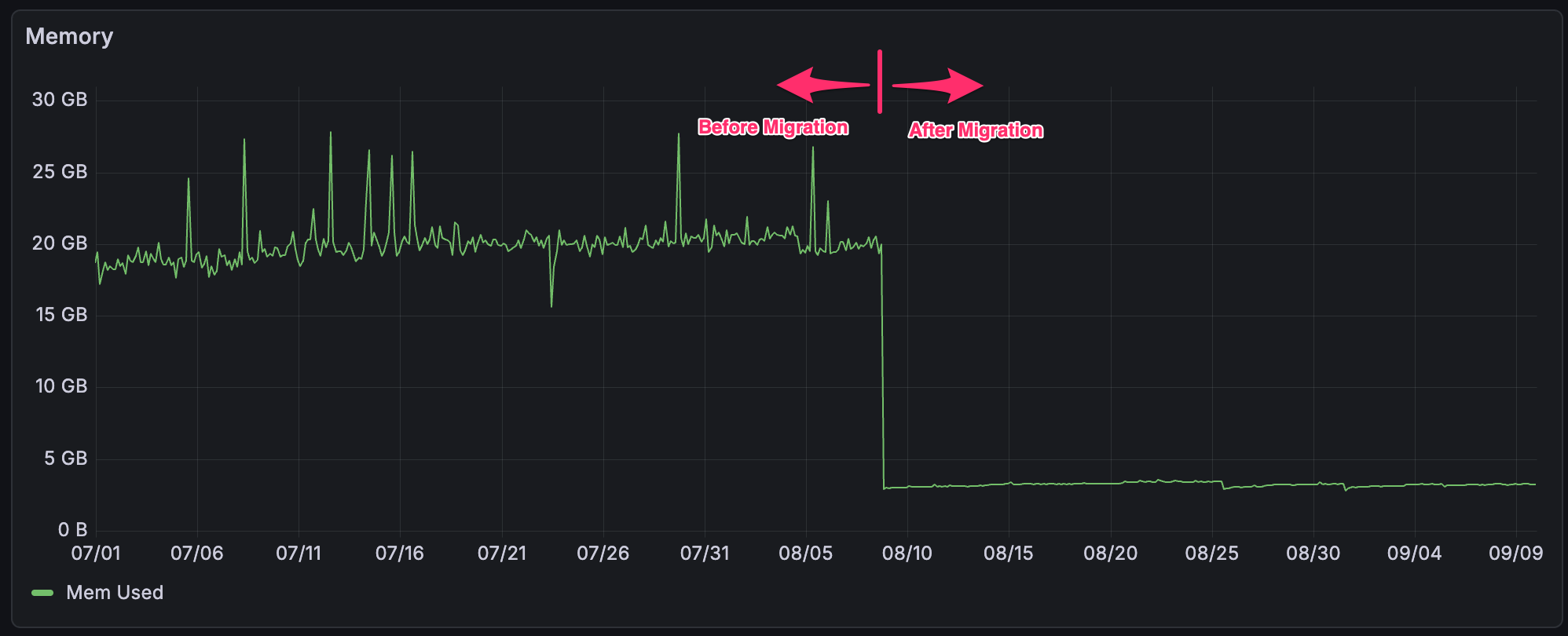
- Reduced Memory/CPU Usage & Greater Stability: PebbleDB’s efficiency and the elimination of BadgerDB’s compaction spikes have cut down resource usage across the board. Depending on the node type, memory utilization has improved by up to 80% and CPU usage by up to 60% after the switch. More importantly, memory usage is now steady over time rather than spiking unpredictably, so nodes are much less likely to crash from out-of-memory errors or stall. Improved stability and predictable resource consumption means a better experience for node operators and more consistent performance for the network as a whole.
- Lower Hardware Requirements for Node Operators: Because resource usage has dropped meaningfully, Flow has lowered the recommended hardware specifications for nearly every node role. Collection, Consensus, and Verification nodes now run with half the CPU and one-quarter the memory previously required, while Access nodes require half the CPU and half the RAM. These reductions translate directly into lower operating costs and infrastructure footprints.
Overall, migrating from BadgerDB to PebbleDB has made Flow’s node infrastructure more robust, efficient, and easier to manage. Node operators benefit from lower hardware requirements and reduced manual maintenance, while the network gains greater scalability headroom and reliability. This storage upgrade is a key step in ensuring Flow can continue to grow without hitting bottlenecks in its underlying database technology.