

Announcing the open beta launch of the Flow community Archive Node
.png)
We are excited to announce the Open Beta of the Flow community archive node. The archive node provides a scalable and efficient way to access the execution state history of the Flow protocol **for the current spork. It can be used to query for account details and execute scripts at any given block from the start of the current spork to the latest sealed block using the gRPC Access API.
What is an archive node?
The Flow multi-node architecture provides future-proof scaling by separating consensus from execution and having a few resource-rich execution nodes for transaction execution. These execution nodes have been designed to keep the execution state data (state of Flow accounts, smart contracts, resources etc.) in memory for faster access. However, given that the state will continue to grow indefinitely, the execution nodes are designed to keep only the most recent state in memory, going back to around 100 blocks in the past. Hence, there is a need for an efficient solution to serve old or archive execution state data going back further than 100 blocks in the past for any application that would like to query the state at a past block. The archive node aims to provide that solution and serve archive data.
The archive node is a node that follows the chain and stores and indexes both the protocol and the execution state. It allows read-only queries such as script execution that require the execution state register values. It can be used to answer any queries from past data e.g. “what was the Flow account balance at height X?” where X is several thousand blocks in the past.
How does the archive node work?
Like the observer node, the archive node is also an unstaked node and communicates with an upstream access node. The observer node receives only the protocol state data (blocks, collections, transactions etc.), while the archive node receives both the protocol state and the execution state data.
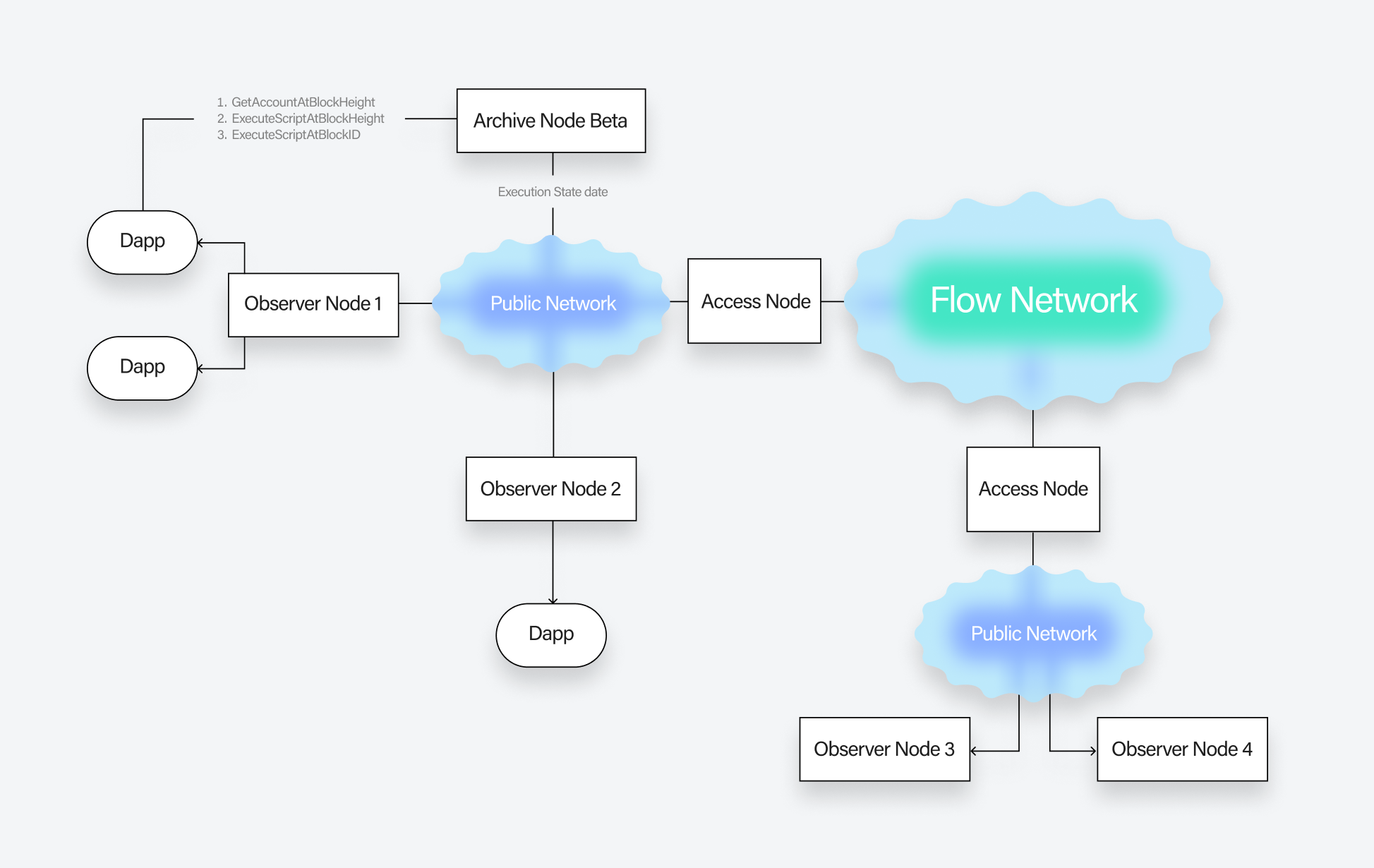
Who should use the archive node?
- dApps which need access to historical data, for example, CAST, which factors in user account balances at a past block
- Chain analytics and auditing tools that require access to historical data
Different nodes for data retrievability - Archive node vs access node vs observer node
Before discussing the difference between the archive node and the access and observer nodes, first, let's look at the two types of state data in Flow. Since Flow has different types of nodes instead of a single validator node, not all node types have all the data. Flow state data is divided into Protocol state data and Execution state data.
Protocol State is the state of the operation of the Flow network protocol, including the identity table and resources produced by nodes in the Flow network: blocks, collections, receipts, approvals, seals, etc.
The Execution State is the state of Flow accounts, smart contracts, resources, etc. This state is stored in full only on Execution nodes.
The access node is a staked node that receives and indexes all protocol state data and serves the Access API. It can reply to all the Access API calls related to the protocol state, such as GetBlock, GetAccount, GetCollection etc., by querying its local database. However, for all calls related to the Execution state e.g. GetAccount, ExecuteScriptAtXXX, it makes an upstream call to an execution node to fetch the execution state data.
Earlier this year, the observer node was launched as an unstaked alternative to the access node that anyone can run without having to stake the node. Like the access node, the observer node also serves the Access API. It only receives and indexes the latest block data and delegates all Access API calls to an upstream access node other than the ones for block data.
Today, one can easily query an access node or an observer node for the account balance at the latest block, or execute a script at the latest block however you cannot query for account balance or execute the script at any arbitrary block in the past and on doing so you will get an error such as the following since the execution nodes do not retain execution state data beyond 100 blocks in the past,
rpc error: code = Internal desc = failed to get account: failed to get account at block (xxx): state commitment not found (yyy). this error usually happens if the reference block for this script is not set to a recent block.
This is where the archive node comes in.
Unlike the access node and the observer node, the archive node stores and indexes the Execution state in addition to the Protocol state data. It can then reply to Execution state Access API calls such as GetAccount through its local database.
- If you want access to the latest blocks, transactions etc., but don’t want to run a node, use the Flow community Access Node.
- If you want a single tenancy and/or don’t want to be subjected to the Access API rate limits, consider running your own access node.
- If you want a locally running node that provides the latest block data, run an observer node.
- If you want to access historical execution state data, use the community archive node.
API
The archive node provides a concise version of the gRPC Access API, which includes the following three calls,
- ExecuteScriptAtBlockID
- ExecuteScriptAtBlockHeight
- GetAccountAtBlockHeight
It returns an HTTP error 501 Not implemented for all other Access API calls.
The gRPC API endpoint is: archive.mainnet.nodes.onflow.org:9000
Examples
1. To get an Account balance at the start of the current spork, you can call the GetAccountAtBlockHeight on the archive node.
Sample code:
package main
import (
"context"
"fmt"
"github.com/onflow/flow-go-sdk/access/grpc"
"github.com/onflow/flow-go-sdk"
)
func main() {
// the Flow community archive API endpoint
archiveNodeAddress := "archive.mainnet.nodes.onflow.org:9000"
// create a gRPC client for the Archive node
archiveNodeClient, err := grpc.NewClient(archiveNodeAddress)
if err != nil {
fmt.Println("err:", err.Error())
panic(err)
}
ctx := context.Background()
addr := flow.HexToAddress("e467b9dd11fa00df") // any Flow account address
// get Account balance at the start height of the current spork
// <https://developers.flow.com/nodes/node-operation/past-sporks#mainnet-20>
account, err := archiveNodeClient.GetAccountAtBlockHeight(ctx, addr, 40171634)
if err != nil {
fmt.Println("err:", err.Error())
panic(err)
}
fmt.Println(account.Balance)
}
2. To execute a script at a block in the past, you can call the ExecuteScriptAtBlockHeight or the ExecuteScriptAtBlockID call on the archive node.
Sample code:
package main
import (
"context"
"fmt"
"github.com/onflow/cadence"
"github.com/onflow/flow-go-sdk/access/grpc"
)
func main() {
// the Flow mainnet community Access node API endpoint
accessNodeAddress := "access.mainnet.nodes.onflow.org:9000"
// the Flow community archive API endpoint
archiveNodeAddress := "archive.mainnet.nodes.onflow.org:9000"
// create a gRPC client for the Access node
accessNodeClient, err := grpc.NewClient(accessNodeAddress)
if err != nil {
fmt.Println("err:", err.Error())
panic(err)
}
ctx := context.Background()
// get the height of the latest sealed block from the Flow mainnet community access node
latestBlockHeader, err := accessNodeClient.GetLatestBlockHeader(ctx, true)
if err != nil {
fmt.Println("err:", err.Error())
panic(err)
}
// set height to 500 blocks in the past
height := latestBlockHeader.Height - 500
// create a gRPC client for the Archive node
archiveNodeClient, err := grpc.NewClient(archiveNodeAddress)
if err != nil {
fmt.Println("err:", err.Error())
panic(err)
}
script := []byte(`
pub fun main(a: Int): Int {
return a + 10
}
`)
args := []cadence.Value{cadence.NewInt(5)}
// execute script on the archive node at a block height which is 500 blocks in the past
value, err := archiveNodeClient.ExecuteScriptAtBlockHeight(ctx, height, script, args)
if err != nil {
fmt.Println("err:", err.Error())
panic(err)
}
fmt.Printf("\\nValue: %s", value)
}
Limitations
- gRPC API rate limits
- The Access REST API and gRPC-web endpoint are currently not supported.
- The archive node currently cannot be self-hosted.
- The archive node can only go back till the start of the current spork.
Node Status
The status of the archive node can be monitored from the Flow status page under “Flow mainnet archive node components”
What's next 🚀
This is an open beta launch as we iron out the kinks and get the archive node ready for a GA launch early next year.
The community archive node will always be available, and early next year, there will be a self-hosted version of the archive node that anyone can run as part of the path to permissionless node operation roadmap. This beta launch is a stepping stone toward that goal.
Feedback ❤️
We value your feedback. Please report any issues that you find when using the archive node here: https://github.com/onflow/flow-archive/issues.


